The ASIC-GPU Standoff
My friend Liberty recently highlighted an interesting paper from Google that goes through the evolution of TPUs. The objection to domain-specific silicon which might sound quite persuasive is the one about obsolescence: a chip may take two to three years to design, fabricate, and deploy, and AI moves fast enough that whatever you tuned it for has usually moved on by the time it lands in a data center; you may end up optimizing for a workload that no longer exists while a GPU runs whatever the labs may cook up next quarter. So, Google’s bet on TPU was somewhat contrarian but thankfully, that bet has been on the right side of history so far. From the paper (emphasis mine):
Skeptics initially warned that an ASIC might be too tailored to existing DNN (Deep Neural Network) models, quickly becoming outdated given AI’s rapid pace. That proved not to be the case. The founding principles of TPU v2 demonstrated remarkable longevity, with later generations increasing component speed and size by riding technological breakthroughs without altering the underlying design. Not all accelerators can make this claim.
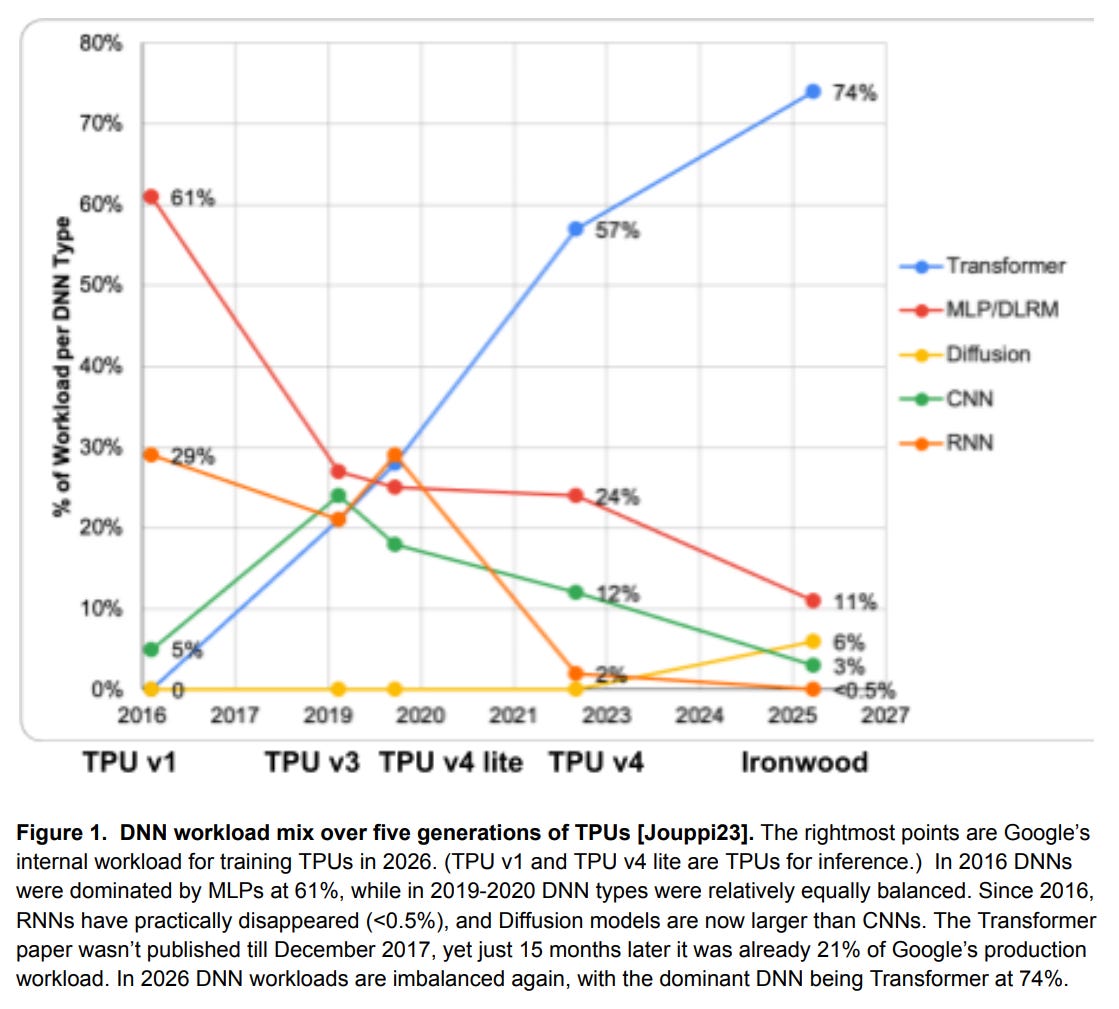
The paper quipped that TPU’s success has “launched a thousand chips”. Indeed, the latest ASIC that grabbed a lot of attention is OpenAI’s Jalapeño chip, its first in-house inference chip, built with Broadcom and Celestica. Unlike most press releases, this one is worth reading carefully. Here are some key excerpts (emphasis mine):
OpenAI designed the chip from scratch around its deep understanding of LLM fundamentals, informed by its roadmap of models, kernels, serving systems, and product needs, with partners Broadcom and Celestica, helping industrialize the platform through chip implementation, board, rack system integration, high-performance networking, and scalable production systems. Jalapeño is designed with flexibility to work with all LLMs guided by OpenAI’s insights into the inference needs of current and future AI models across the industry. Engineering samples of the Jalapeño chip are running ML workloads in the lab at production target frequency and power, including GPT‑5.3‑Codex‑Spark.
While OpenAI is still measuring final performance, early testing shows that Jalapeño will deliver performance per watt substantially better than current state-of-the-art. A detailed technical report on performance will be presented in the coming months. The architecture reduces data movement and balances compute, memory, and networking resources to achieve realized utilization much closer to theoretical peak performance.
Jalapeño was co-developed from initial design to manufacturing tape-out in just nine months, and the custom AI accelerator program represents what we believe to be the fastest ASIC development cycle ever achieved in high-performance advanced semiconductors. That speed reflects deep software-hardware co-development with OpenAI’s engineering teams, Broadcom’s silicon implementation expertise, and the use of OpenAI models to accelerate parts of the design and optimization process.
Jalapeño is the first step in a multi-generation compute platform designed for initial deployment by the end of 2026 and expanding in the years ahead, combining OpenAI-designed accelerators with Broadcom silicon implementation, networking, and connectivity technologies; and Celestica’s board, rack, and system expertise.
Going through that press release is a good reminder how damn useful owning the model layer can be. There may be capability overhang as the models are likely to be far more capable than what most people use it for, but the very researchers developing these models should be in the best seat to extract the highest capabilities out of these frontier models. Of course, such fast paced LLM-optimized chip design does raise question around the depth of moat around Nvidia’s CUDA. I myself wondered last year that this question will inevitably be raised:
A good chunk of Nvidia’s moat comes from CUDA (Compute Unified Device Architecture) which is a parallel computing platform and programming model that has created immense developer lock-in. CUDA exists to bridge the gap between human programmers and the complex architecture of the GPU. As AI systems become capable over time, AI should not require human-friendly abstraction layers, SDKs, or documentation. It could theoretically look at any piece of hardware i.e. an Nvidia GPU, a Google TPU, or a novel architecture it just designed and write perfectly optimized machine code for it. If humans are increasingly out of the loop, shouldn’t the friction that keeps developers locked into CUDA also materially diminish over time?
Jensen Huang was actually directly asked about this a couple of months ago during his podcast with Dwarkesh:
Dwarkesh:
Can all the hyperscalers write these custom kernels for themselves? Nvidia still has great price performance, so they might still prefer to use Nvidia. But then the question is, does it just become a question of who is offering the best specs, the best flops and memory bandwidth for a given dollar. Whereas historically Nvidia has just had, and still has, the best margins in all of AI across hardware and software, +70%, because of this CUDA moat. And the question is, can you sustain those margins if for most of your customers, they can actually afford to build, instead of the CUDA moat?
Jensen Huang
The number of engineers we have assigned to these AI labs is insane, working with them, optimizing their stack. The reason for that is because nobody knows our architecture better than we do. These architectures are not as general purpose as a CPU. A CPU is kind of like a Cadillac. It’s a nice cruiser. It never goes too fast. Everybody drives it pretty well. It’s got cruise control, and everything’s easy. But in a lot of ways, Nvidia’s GPUs, accelerators, are like F1 racers. I could imagine everybody’s able to drive it at a hundred miles an hour, but it takes quite a bit of expertise to be able to push it to the limit. We use a ton of AI to create the kernels that we have.
Huang likes to call Nvidia an “extreme co-design company,” and that’s where much of the magic comes from, but it stops being a uniquely Nvidia trick once a customer controls most layers and points its own models at optimizing across them. Even though CUDA moat may be diminishing in the age of increasingly more and more capable frontier models, Nvidia’s moat is likely to be fine in the near term given their control across the supply chain, but long-term questions cannot quite be resolved.
Speaking of supply chain, Rihard Jarc recently shared an interesting interview of a Google employee who has hinted at the possibility of hyperscalers building a more direct relationship with TSMC. Maybe TSMC’s CEO won’t need to utter “customers’ customers” for too long in their earnings calls! Some key points from Rihard’s post:
Interview with a Google employee explaining that the value when it comes to ASIC design from companies like AVGO, Mediatek, and MRVL is in their TSMC allocation, not the co-design anymore:
1. When it comes to co-design of chips, he thinks the real value of companies like AVGO, Mediatek, and MRVL lies in their TSMC allocation and memory allocation, which they got sooner than everyone else. In the whole process, he sees platform verification and then manufacturing as key.
2. If you could flip a switch and completely reset the TSM allocation, he thinks the hyperscalers would move 100% to internal co-design and skip the co-designers for that part. There is still value in AVGO‘s IP for memory, or in MRVL’s interconnects, but for co-design specifically, he thinks it comes down to TSMC and the memory supply chain allocation.
3. In the future, he thinks hyperscalers will move to direct TSMC relationships.
Huang is, of course, acutely aware of how his top customers are all deeply incentivized to design their own chips and it’s hard to bet on such well-capitalized customers NEVER getting there. This is perhaps why Nvidia itself is also on their own journey of building open-weight models. Any time there is a monopoly formed in some parts of the AI value chain is not good news for the rest of the value chain. If Anthropic or OpenAI ends up with a monopoly or stable duopoly without a viable open-weight alternative (assuming China open-weight models get eventually banned in the US), you can see the pressure the likes of Nvidia and 3P hyperscalers might feel eventually to extract margin from OpenAI/Anthropic. With Meta sending not-so-reassuring signals about their approach to open-weight AI models, Nvidia is trying to lead the open-weight models in the West. The equation is simple: everyone wants fragmentated customer base for whatever they’re selling and the moment your customer base becomes too concentrated, it’s hard to sit idle and pray/hope that such customers will forever pay your margins. In some sense, much of the AI value chain increasingly feels like this below meme from “The Office” and it’s not easy to know how all of these debates will largely settle in 3-5 years.

Subscribers get the daily journal and five+ years of Deep Dives, i.e. full-length analyses with financial models on 65+ companies. The daily is just how I think out loud between the Deep Dives!
Disclaimer: All posts on “MBI Deep Dives” are for informational purposes only. This is NOT a recommendation to buy or sell securities discussed. Please do your own work before investing your money.