The Pendulum Between Intelligence and Knowledge
Over the last week or so, I have started noticing an interesting development that is worth highlighting.
Let’s start with Microsoft’s announcement yesterday. From Microsoft’s blog yesterday (emphasis mine):
“Today, Researcher—Microsoft 365 Copilot’s deep research agent for work—takes a significant step forward. Designed to tackle complex research in the flow of work, Researcher now goes further with two new multi-model capabilities that raise the bar for accuracy, depth, and confidence: Critique and Council.
Critique is a new multi model deep research system designed for complex research tasks. It separates generation from evaluation and utilizes a combination of models from Frontier labs including Anthropic and OpenAI. One model leads the generation phase, planning the task, iterating through retrieval, and producing an initial draft, while a second model focuses on review and refinement, acting as an expert reviewer before the final report is produced. Our evaluations show that this architecture exceeds traditional single model approaches and delivers best in class deep research quality. This design provides clear optionality across generator and reviewer roles, with the ability to support and expand these roles over time as the system evolves.
Council brings multiple model responses side-by-side in the Researcher experience. Additionally, a cover letter provides valuable insights on where the models agree, where they diverge, and the unique insights each brings on the topic.”
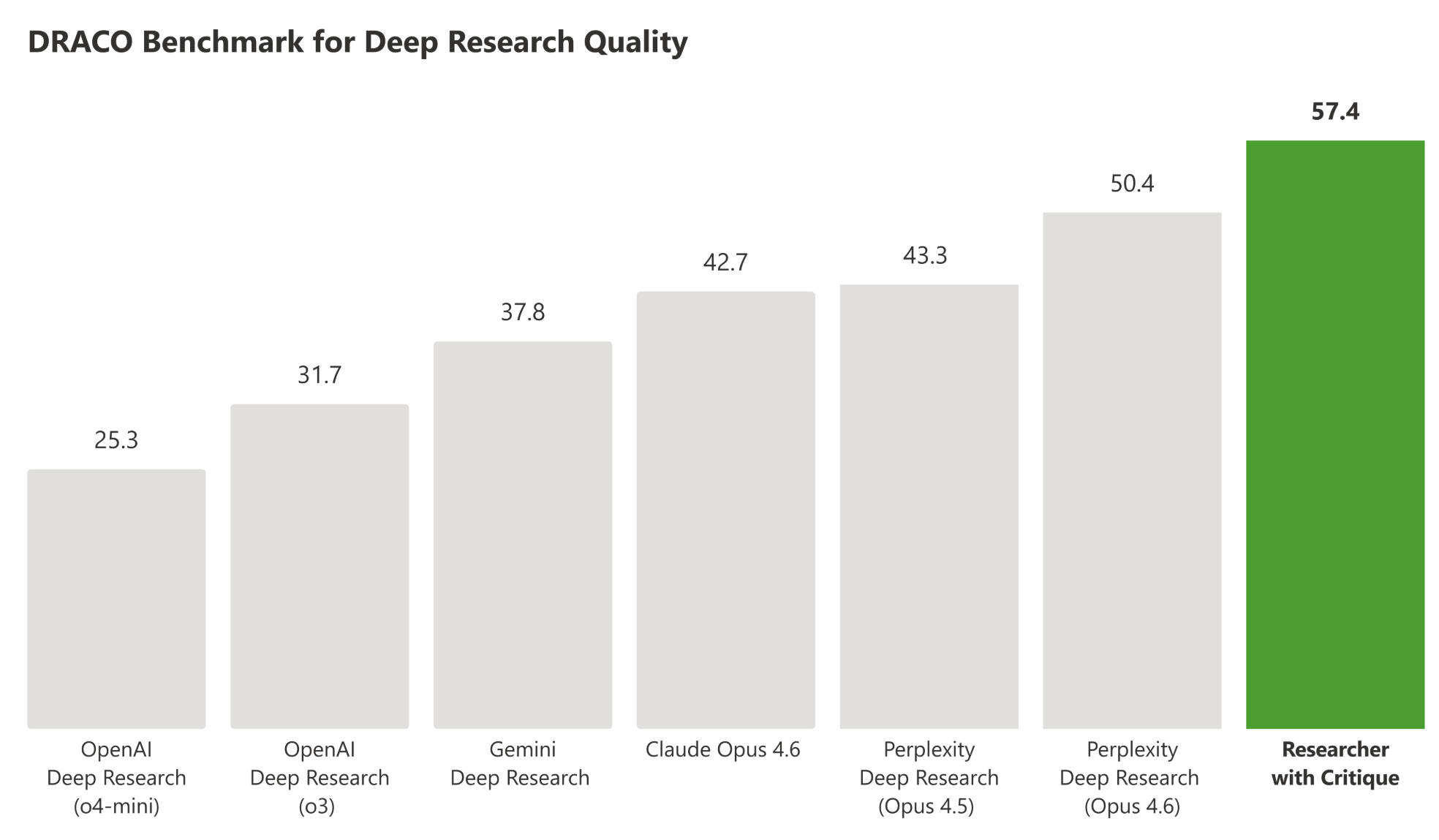
As someone who often copies and pastes the same queries to ChatGPT, Gemini, and Claude and then manually reads their responses and evaluates the quality afterwards, I can certainly see the appeal for a product such as “Council”. “Critique” is perhaps more useful if you want to automate something (hence you’re not in the loop) and want to ensure AI’s work goes through multiple phases of refinement before it presents the final work to you.
Let’s move onto Intercom now which is a customer service suite software company. Intercom shipped their own customer service AI model called “Fin Apex 1.0”. From Intercom’s blog this week (emphasis mine):
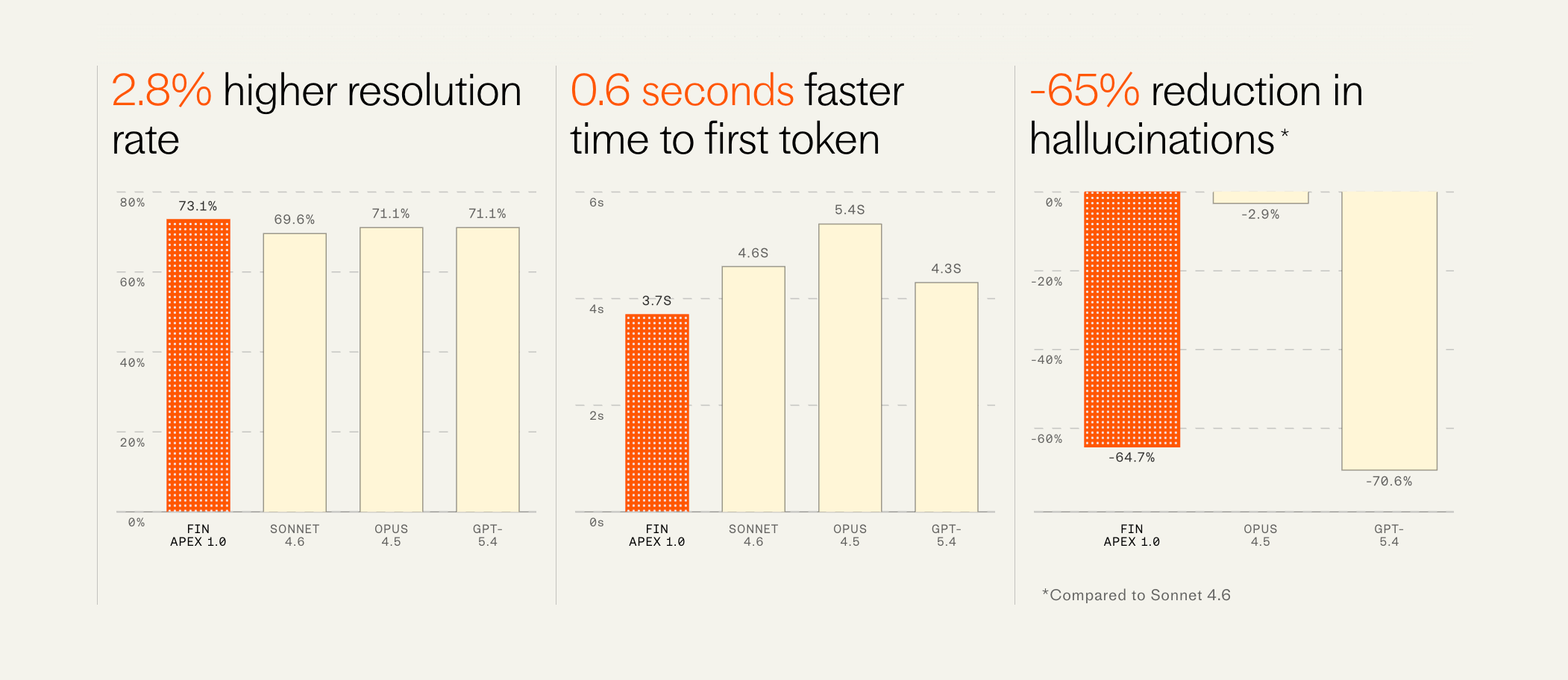
“As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year we started replacing the off-the-shelf models with our own, custom trained on our proprietary data. But the core answering model was always a frontier labs offering—initially versions of GPT and recently Sonnet 4.0. But now that core answering model is Apex 1.0.
This model resolves customer issues at a materially higher rate than any other model available. One of our largest customers in the gaming space saw their resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). We’ve never seen a jump this large from a single improvement since we started Fin.
But importantly it’s also dramatically faster, has fewer hallucinations, and is far cheaper than all other available models—all factors that weigh significantly in the consideration of companies deploying these agents to their service operations.”
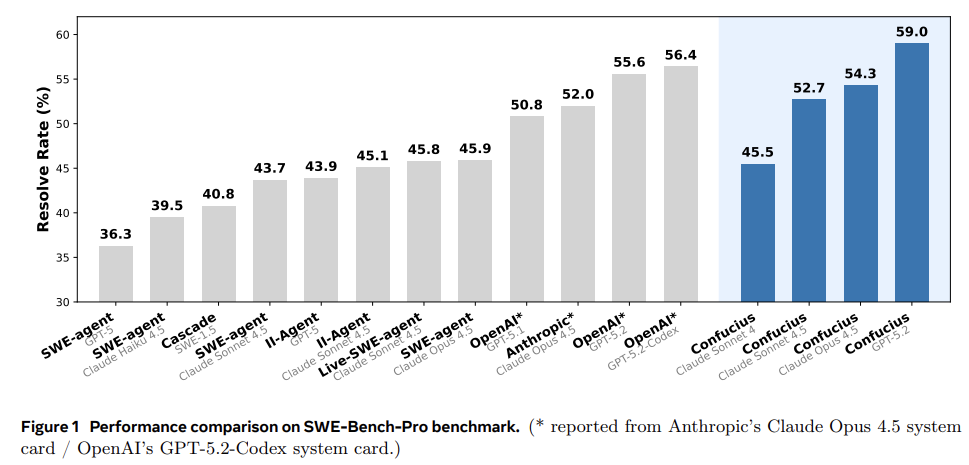
Last week, I also highlighted a paper by Meta in my piece “Meta’s Agentic AI Ambitions”. From my piece:
The most interesting takeaway from the paper is that a great setup can compensate for a less powerful AI. The researchers proved that a weaker model (Claude 4.5 Sonnet) using the Confucius scaffolding successfully fixed more bugs (52.7%) than a stronger, more expensive model (Claude 4.5 Opus) using Anthropic’s standard setup (52.0%). When powered by the GPT-5.2 model, Confucius Code Agent successfully resolved 59% of the real-world bugs on the SWE-Bench-Pro test, beating both prior academic research and the official corporate systems built by OpenAI and Anthropic under identical conditions.
Behind the paywall, I will share some thoughts what these different announcements hint at the future of AI and potential implications for frontier model developers.
In addition to “Daily Dose” (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 67 Deep Dives here.