Owning the Hill
Satya Nadella spent part of last weekend writing a think piece on X titled “A frontier without an ecosystem is not stable”. I mostly nodded along while reading the piece, but there was also a lot of cynicism from many corners about his prescription of not mortgaging your IP to frontier AI labs as Nadella is clearly talking his book. I do believe Nadella’s posture is defensive, but he’s putting his fingers on the right areas even if he’s making points that are self-serving. What really stood out to me is Nadella’s point about creating a compounding loop that can be largely immune from ever improving frontier model capabilities. From Nadella’s post:
Companies need to turn their workflows, domain knowledge, and accumulated judgment into AI systems that improve with each use. Private evals should capture whether a model is actually improving against outcomes that matter to the business (not just external benchmarks!). Private reinforcement learning environments should let models grow stronger on real traces from inside the organization. Its knowledge base makes institutional memory queryable and use of tokens more efficient.
This loop becomes the new IP of the firm. I think of it as a hill climbing machine. And unlike most assets, it compounds. Every improved workflow generates better training signal, which accelerates the accumulation of tacit knowledge unique to the firm. The companies that build this early will have an advantage that is hard to replicate, regardless of any new individual model capability.
Indeed, a couple of months ago in my piece “The Pendulum Between Intelligence and Knowledge”, I highlighted Fin (formerly known as Intercom) which was able to climb the hill in a way Nadella would find gratifying. From Fin’s blog post in March 2026:
“As of last week, ~100% of all (English language, chat and email) customer conversations are now running on Apex. Since day 1, the Fin engine has comprised a system of models, and last year we started replacing the off-the-shelf models with our own, custom trained on our proprietary data. But the core answering model was always a frontier labs offering—initially versions of GPT and recently Sonnet 4.0. But now that core answering model is Apex 1.0.
This model resolves customer issues at a materially higher rate than any other model available. One of our largest customers in the gaming space saw their resolution rate improve overnight from 68% to 75% (i.e. a reduction in unresolved conversations of 22%). We’ve never seen a jump this large from a single improvement since we started Fin.
But importantly it’s also dramatically faster, has fewer hallucinations, and is far cheaper than all other available models—all factors that weigh significantly in the consideration of companies deploying these agents to their service operations.”
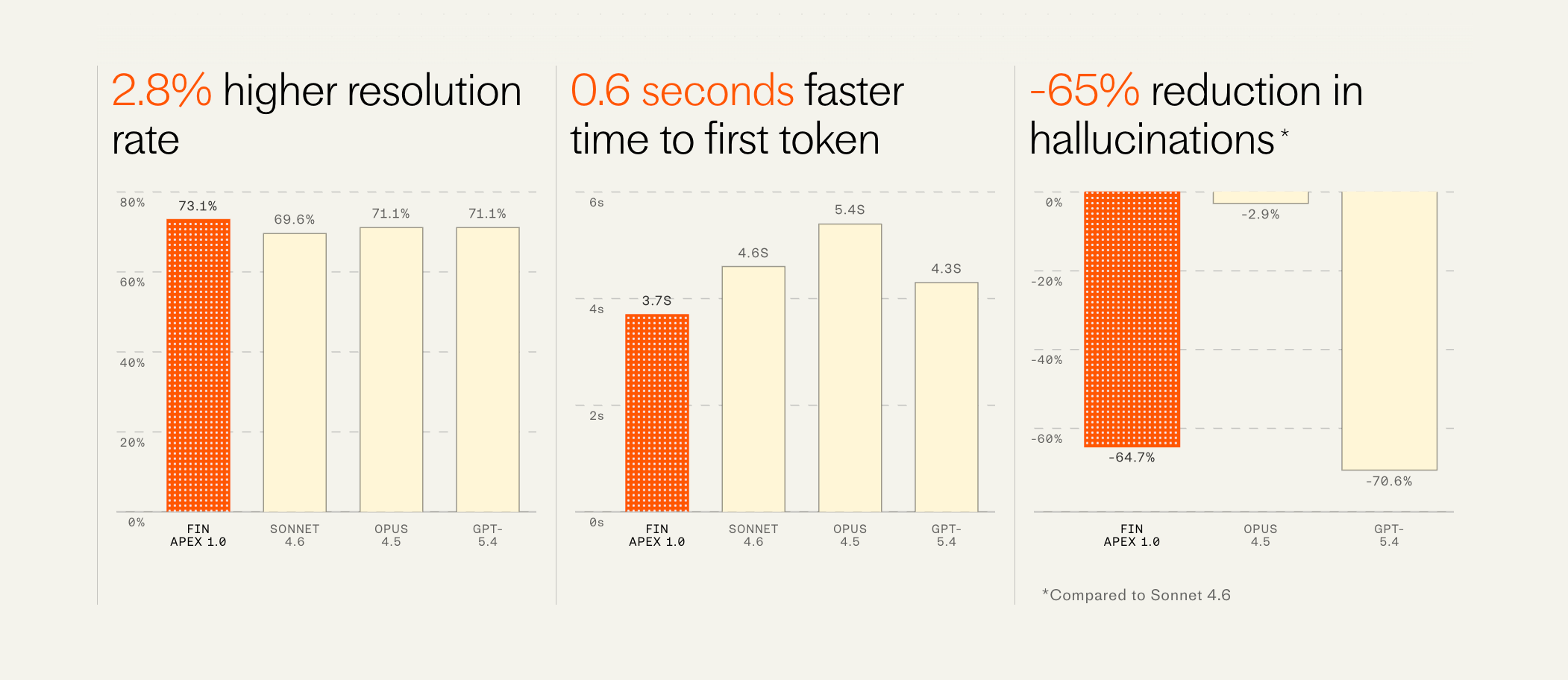
Perhaps it’s telling that Fin just got acquired by Salesforce yesterday.
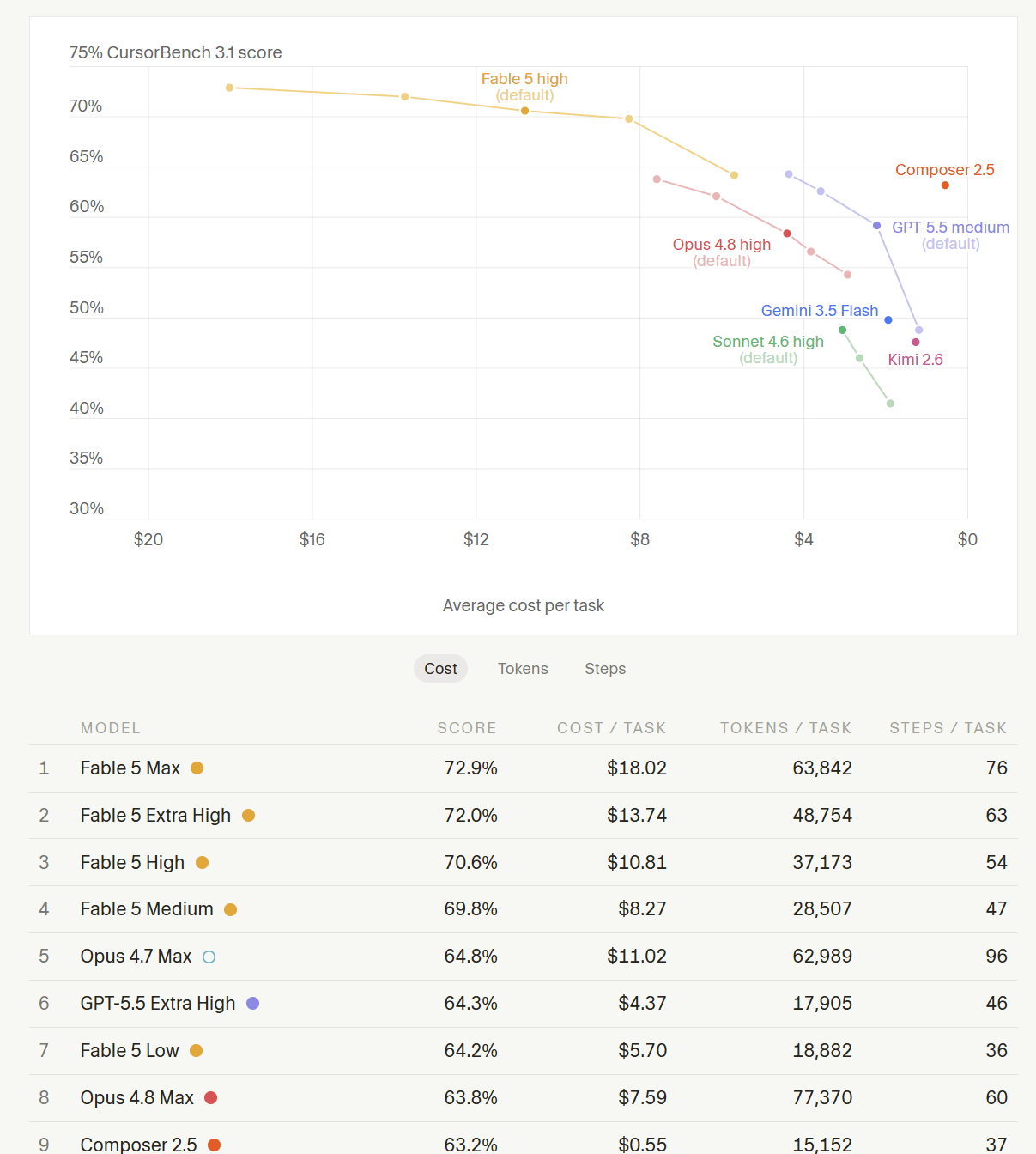
Speaking of acquisition, SpaceX just decided to acquire Cursor for $60 Billion. Cursor was perhaps one of the first companies to realize the conundrum of not owning the hill. Business Insider yesterday reported that Anthropic initially told Cursor that Claude Code was just a 'research effort'. I suspect this might be a recurring theme from the frontier labs; anytime there is a compelling product market fit that has potentially large addressable market, labs won’t be able to help themselves from building a first-party product to gobble that market. Cursor has been trying to respond to that risk the way Nadella would certainly approve. They built a private benchmark, "CursorBench," made of real requests from real users, and trained its Composer models with RL against it, grading not just correctness but adherence to a codebase's existing abstractions and software engineering practices. You can see the importance of having such private benchmark below. Please note that the x-axis runs backwards i.e. cost per task falls from $20 on the left to $0 on the right, so the model you want lives in the top-right corner (high score, low cost), not the top-left. Each colored line is a single model dialed across its effort settings, from Low up to Max; as you crank the reasoning effort, the dot climbs but slides left, buying a few more points of score for a lot more tokens, steps, and dollars.
The curves are concave, and that concavity is the point: diminishing returns on compute. Fable 5 Medium scores 69.8% at $8.27, while pushing the same model to Max buys 72.9% at $18.02 which is roughly double the spend for three points. Composer 2.5, Cursor's own in-house model, manages 63.2% for just 55 cents and ~15,000 tokens, while Opus 4.8 at full effort barely beats Composer 2.5 but spends ~5x tokens and costs ~14x more for the same task!
Once you have your private eval, the loop can feed itself: a better model ships, serves more users, generates more and better traces and surfaces new failure modes, which expand the eval and the training set, which yields a better model.
A recent paper titled “Test-Time Compute Games” also drove the point home to me why not having such private eval can be potentially quite damaging for companies running blind as there is a huge incentive misalignment between model providers and their customers. From the paper:
“…providers have the flexibility to (dynamically) adjust the amount of test-time compute an LLM uses to respond to a user’s query. However, in a competitive market, this flexibility creates a new strategic dimension beyond how providers price their services. In particular, providers can strategically increase the amount of test-time compute allocated to a user’s query to maximize profit, even if the additional test-time compute contributes little to the quality of the response. Consider a simple illustrative example where, for a given set of queries with verifiable ground truth (e.g., diagnosing patients based on their medical records), two different providers can run their LLMs in either a low-TTC (test time compute) mode (e.g., standard generation) or a high-TTC mode (e.g., chain-of-thought), with average accuracies and generation costs for the providers given by:

If both providers price their models with a 25% profit margin over their generation costs, it is easy to see that a user who values each percentage point of accuracy as $0.02 would always select the first provider, who offers them higher value (i.e., $0.02 × accuracy − price) independently of the TTC mode chosen by the second provider. However, to increase their profit, the first provider is financially incentivized to choose the high-TTC mode, even though the low-TTC mode would maximize the sum of the user value and provider profit, and would therefore be socially optimal.”
As you can imagine, if you rent intelligence, you cannot inherently control the meter; the counterparty does, and its incentives are structurally misaligned with yours as it profits from selling you a longer, costlier path up the same hill. Without your own evals, you cannot tell whether the compute you’re paying for bought you anything more useful worth paying for. The provider, of course, knows but you’ll be just guessing. Despite this compelling logic, the reality is most tech companies don’t seem to have woken up to this conundrum yet. Perhaps Nadella’s post will finally jolt them out of such inertia and push them to give their best shot at owning their destiny instead of being just another wrapper without any compounding loop.
Subscribers get the daily journal and five+ years of Deep Dives, i.e. full-length analyses with financial models on 65+ companies. The daily is just how I think out loud between the Deep Dives!
Current Portfolio
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: