On the eve of Gemini 3.0
Prediction markets indicate Alphabet will release Gemini 3.0 next week. Sundar Pichai’s tweet also makes it all but certain that is indeed likely the case. At least my twitter or X timeline is increasingly filled with tweets from Alphabet employees with giddy excitement about the launch. It’s not just internal folks; many people who got a glimpse of the model’s capabilities have also been posting about pretty effusively. It is perhaps the first time I have noticed such a reaction on the eve of a launch of a model by Google.
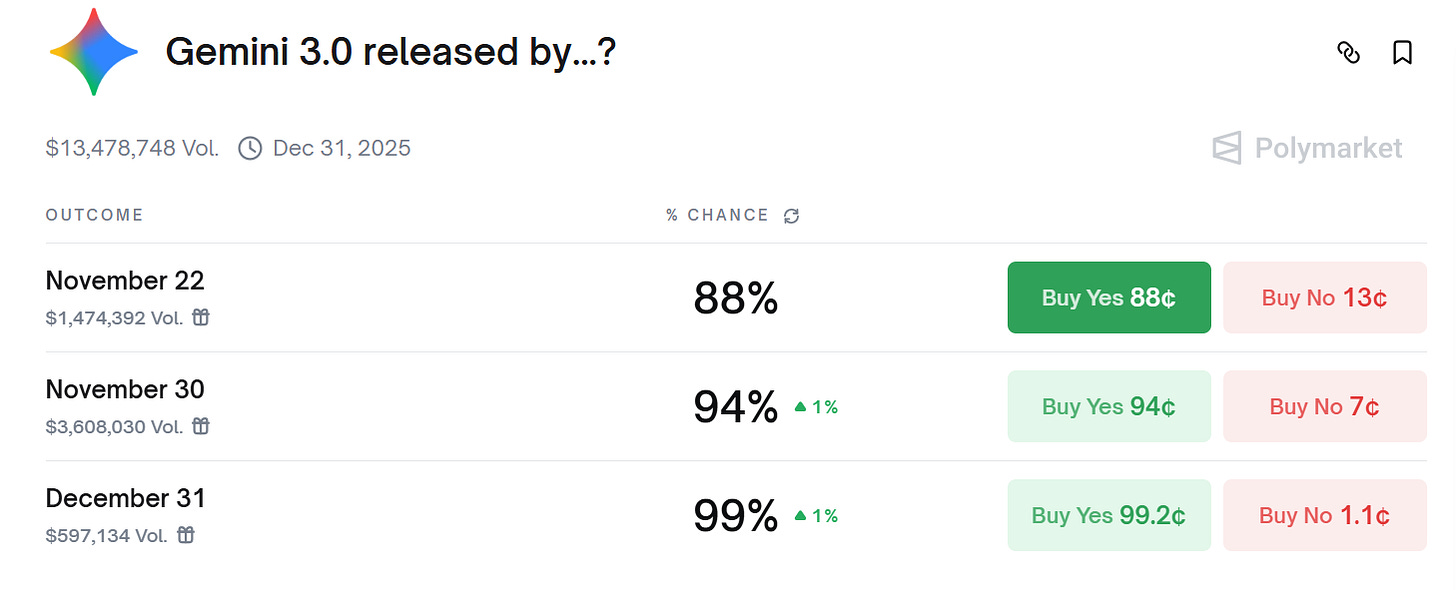
I haven’t got a chance to play with the model yet, and given the level of anticipation, I suspect there is a decent chance that the model may underwhelm many people. Frankly speaking, I am not confident that I can tell any noticeable difference between the models anymore for the kind of queries I like to ask. I usually run the same queries simultaneously in both Gemini and ChatGPT and while I still have slight preference for ChatGPT, it is far from a strong preference these days. It won’t surprise me if that remains the case even after Gemini 3.0.
While the differentiation between the models will likely remain an open question, it does seem extremely likely that model capabilities will almost certainly keep improving over time. Even if it may not be quite apparent to most users, I have recently read an interesting piece by Mark Humphries (Professor of History at Wilfrid Laurier University) on Gemini 3.0’s alleged capabilities that helped me appreciate why people closest to building these models seem to be “AGI” pilled. Of course, there is a cynical view that these people are incentivized to propagate such beliefs, but I think it is perhaps also worth pondering that such beliefs may be earnestly warranted.
Mark Humphries says an unreleased Google model he accessed via Google AI Studio (appearing as an A/B test with two answers to pick from) is nearly perfect at handwritten text recognition (HTR) on messy 18th‑century manuscripts and also shows spontaneous, step‑by‑step symbolic reasoning. He (and others) speculate this may be a Gemini‑3‑era model.
Humphries used his specialized work, which analyzes obscure 18th-century handwritten accounting ledgers, as a benchmark. He notes that this task is exceptionally difficult because it requires more than just visual recognition of messy script; it demands an integration of historical context, linguistic nuance, and logical deduction. From the piece:
“Most people think that deciphering historical handwriting is a task that mainly requires vision. I agree that this is true, but only to a point. When you step back in time, you enter a different country, or so the saying goes. People talk differently, using unfamiliar words or familiar words in unfamiliar ways. People in the past used different systems of measurement and accounting, different turns of phrase, punctuation, capitalization, and spelling. Implied meanings were different as were assumptions about what readers would know.
While it can be easy to decipher most of the words in a historical text, without contextual knowledge about the topic and time period it’s nearly impossible to understand a document well-enough to accurately transcribe the whole thing—let alone to use it effectively. The irony is that some of the most crucial information in historical letters is also the most period specific and thus hardest to decipher.”
The model displayed astonishing accuracy in transcription. Humphries reports that the previous state-of-the-art (Gemini 2.5 Pro) achieved a Character Error Rate (CER) of about 4% on these complex documents i.e. roughly equivalent to a professional human transcriber. The new model reduced the CER to just 0.56% and the Word Error Rate (WER) to 1.22%:
“The new Gemini model’s performance on HTR meets the criteria for expert human performance. These results are also 50-70% better than those achieved by Gemini-2.5-Pro. In two years, we have in effect gone from transcriptions that were little more than gibberish to expert human levels of accuracy. And the consistency in the leap between each generation of model is exactly what you would expect to see if scaling laws hold: as a model gets bigger and more complex, you should be able to predict how well it will perform on tasks like this just by knowing the size of the model alone.”
The most profound implication is the potential transition of AI from sophisticated “stochastic parrots” to systems capable of genuine understanding. Again, from his piece:
“The safer view is to assume that Gemini did not “know” that it was solving a problem of eighteenth-century arithmetic at all, but its internal representations were rich enough to emulate the process of doing so. But that answer seems to ignore the obvious facts: it followed an intentional, analytical process across several layers of symbolic abstraction, all unprompted. This seems new and important.
If this behaviour proves reliable and replicable, it points to something profound that the labs are also starting to admit: that true reasoning may not require explicit rules or symbolic scaffolding to arise, but can instead emerge from scale, multimodality, and exposure to enough structured complexity.”
In a narrow sense, near-perfect HTR combined with contextual understanding would allow for the rapid digitization and analysis of centuries of trapped knowledge, potentially rewriting our understanding of the past:
“For historians, the implications are immediate and profound. If these results hold up under systematic testing, we will be entering an era in which large language models can not only transcribe historical documents at expert-human levels of accuracy, but can also reason about them in historically meaningful ways. That is, they are no longer simply seeing letters and words—and correct ones at that—they are beginning to interpret context, logic, and material reality. A model that can infer the meaning of “145” as “14 lb 5 oz” in an 18th-century merchant ledger is not just performing text recognition: it is demonstrating an understanding of the economic and cultural systems in which those records were produced…and then using that knowledge to re-interpret the past in intelligible ways.”
An AI that can reason can begin to automate complex cognitive tasks previously thought to be the exclusive domain of human experts. The implications of such a system can be even more profound than just re-writing our understanding of the past which itself is no small feat!
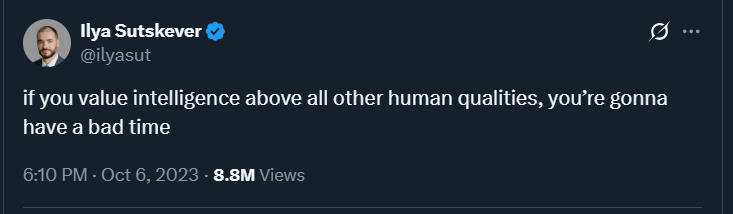
The more I spend time on understanding and covering AI, the more my worldview comes closer to Ilya Sutskever’s tweet a couple of years ago:
In addition to “Daily Dose” (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 64 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: