Google's "first mistake"
I have been listening to Acquired’s latest episode on Google. I haven’t finished the episode yet; I’m half-way into the four-hour episode. As you can imagine, there are a lot of cool anecdotes from the spree of some of the best acquisitions Google has made over the years. I was particularly intrigued by some data from YouTube’s early days.
Following Google’s acquisition, YouTube was generating $30 Million revenue but they were losing $1 Billion per year. We may be accustomed to such numbers today, but Google’s CFO was spooked by the staggering losses. From the podcast:
The amount of money they lost was almost exactly equal to a penny per view. So just imagine every time you loaded YouTube in those years, Google would just flush a penny down the drain. They got to figure out something to do about this. So for the first couple years, the CFO at the time was terrified of it scaling. Like, please don't scale in its current state. But of course, there's nothing they can do. The cat's out of the bag. It's scaling. And the CFO was exploring, hey, can we sell this to one of the other companies who was bidding on it? That's right. Because Yahoo and the media companies also wanted to buy YouTube.
Given this context, apparently YouTube used to be considered Google’s “first mistake”. We may laugh today, but it is an understandable sentiment if you could time travel and imagine yourself looking at this lopsided operating cost structure in late 2000s. It is easy to feel sympathy for the CFO’s fear about YouTube scaling when I heard Acquired mentioning that YouTube in 2007 consumed as much bandwidth as the entire internet did in the year 2000. Even in 2014, YouTube was 20% of the bits on the internet.
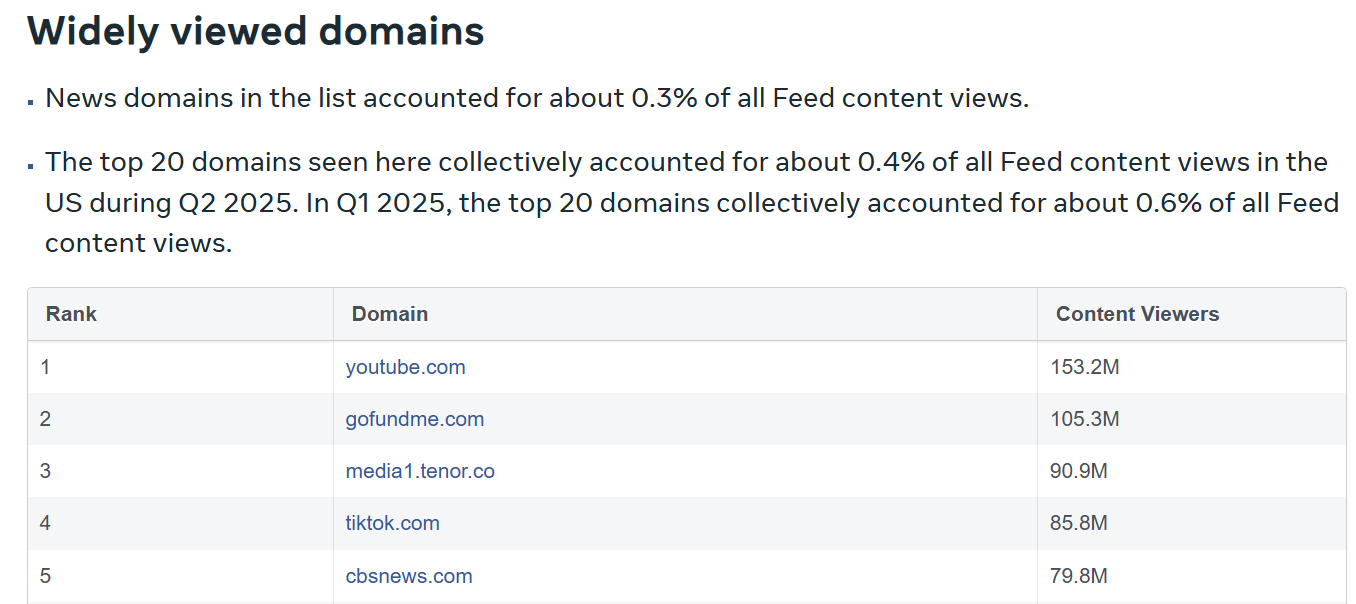
Thankfully, YouTube eventually figured out ways to effectively monetize the aggregated attention. In Q3 2024, YouTube surpassed $50 Billion LTM revenue. More importantly, I think YouTube may prove to be the most durable consumer internet asset. When I was looking at Meta’s recent transparency report, it did catch my attention that YouTube is, by far, the most widely viewed domain on Facebook in Q2 2025.
What’s quite intriguing is the value of YouTube to Google may go far beyond YouTube’s own revenue and profit numbers. A few months ago, Jack Morris made the point that “There Are No New Ideas in AI… Only New Datasets” and it is YouTube which will prove to be the treasure trove of “new datasets”. From his post:
Our breakthrough is probably not going to come from a completely new idea, rather it’ll be the resurfacing of something we’ve known for a while.
But there’s a missing piece here: each of these four breakthroughs enabled us to learn from a new data source:
1. AlexNet and its follow-ups unlocked ImageNet, a large database of class-labeled images that drove fifteen years of progress in computer vision
2. Transformers unlocked training on “The Internet” and a race to download, categorize, and parse all the text on The Web (which it seems we’ve mostly done by now)
3. RLHF allowed us to learn from human labels indicating what “good text” is (mostly a vibes thing)
4. Reasoning seems to let us learn from “verifiers”, things like calculators and compilers that can evaluate the outputs of language models
…The obvious takeaway is that our next paradigm shift isn’t going to come from an improvement to RL or a fancy new type of neural net. It’s going to come when we unlock a source of data that we haven’t accessed before, or haven’t properly harnessed yet.
One obvious source of information that a lot of people are working towards harnessing is video. According to a random site on the Web, about 500 hours of video footage are uploaded to YouTube *per minute*. This is a ridiculous amount of data, much more than is available as text on the entire internet. It’s potentially a much richer source of information too as videos contain not just words but the inflection behind them as well as rich information about physics and culture that just can’t be gleaned from text.
It’s safe to say that as soon as our models get efficient enough, or our computers grow beefy enough, Google is going to start training models on YouTube. They own the thing, after all; it would be silly not to use the data to their advantage.
So, it is certainly in the realm of possibility that Google’s “first mistake” can eventually prove to be its true savior.
In addition to "Daily Dose" (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 62 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: