Frontier AI's Economic Engine
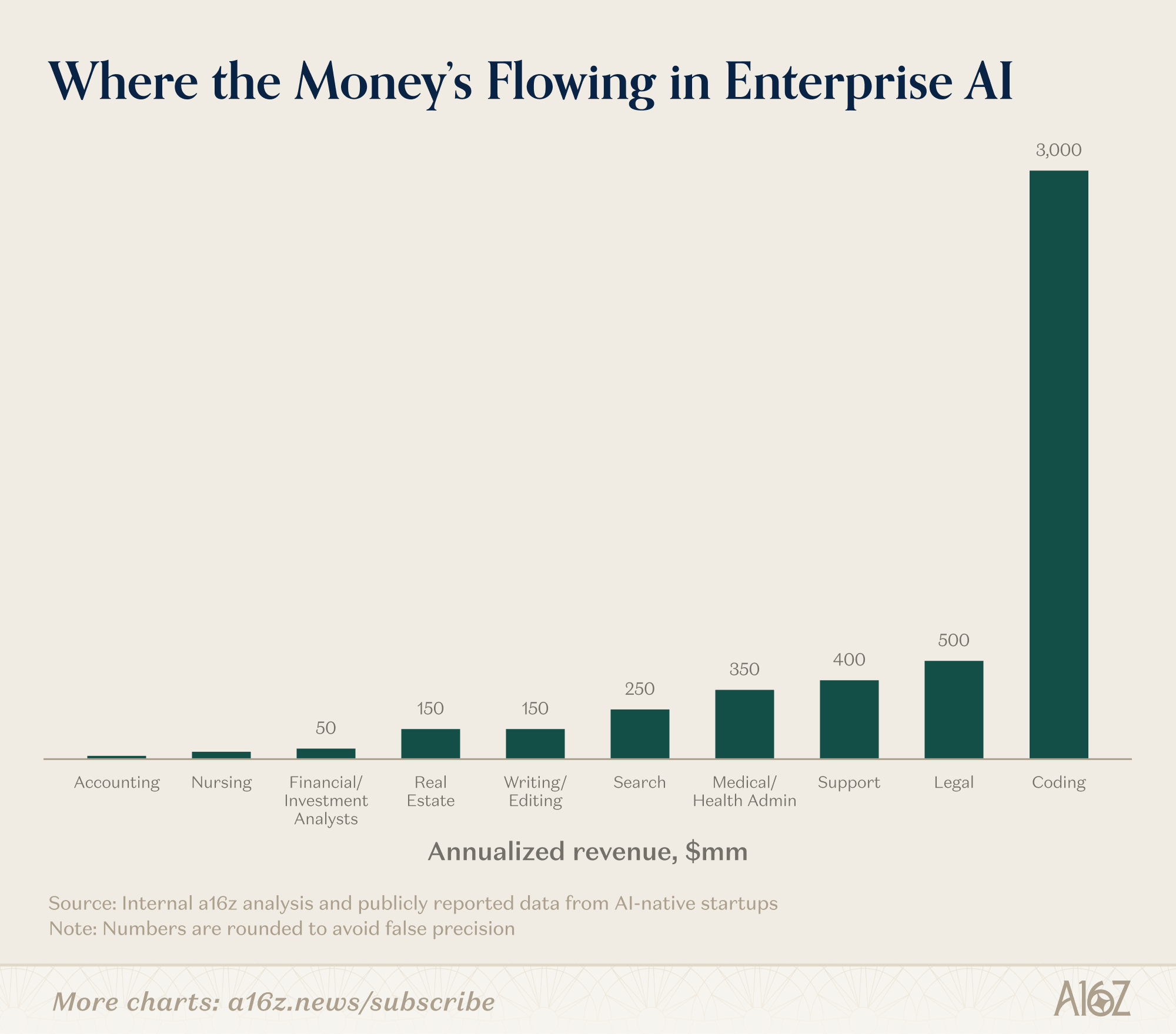
It should not surprise anyone that coding has found the most product market fit in AI, but it is notable that how much it surpasses everything else in enterprise segment so far which explains so much why Anthropic has been on a tear. a16z recently highlighted AI’s adoption and use cases of AI in the enterprise world. From a16z:
“On the revenue momentum, enterprise adoption of AI is dominated by a clear set of use cases and industries. Coding, support, and search represent the lion’s share of use cases by far (with coding being an order-of-magnitude outlier even among this set), while the tech, legal, and healthcare sectors have been the industries most eager to adopt AI.”
It may be obvious to most people, but it is still worth spelling out why coding is such a perfect use case for AI. Again, from 16z (emphasis mine):
In many ways, coding represents the ideal use case for AI, both in terms of what the technology can do and how readily the enterprise market will embrace it. Code is data dense, meaning there is a massive amount of high-quality code available online for the models to train on. It is also text-based, making it easy for models to parse. It is precise and unambiguous, with strict syntax and predictable outcomes. And crucially, it is verifiable: anyone can run it and know if it works, creating tight feedback loops for models to learn from and improve.
Anthropic has been quite focused on nailing the coding use case for the last couple of years as they believe it can not only accelerate their own research but also provides the most compelling economic return. From Sholto Douglas on a podcast 6 months ago why Anthropic has been so focused on coding (emphasis mine):
Two reasons.
First, we think it’s the thing that will allow us to assist ourselves in AI research faster. There’s this notion of automating AI research. The speed of takeoff—the speed of progress—is driven by how much AI can assist AI research. Pre-fetching this is important.
Second, we think coding is the nearest‑term tractable problem domain in terms of economic impact. For Anthropic to be a viable research program that can work on the things we think are important, we need economic return. Coding is a huge market full of keen early adopters who are excited to try and switch tools.
There’s massive demand. There is dramatically more demand for software than there is good software. We’ve seen this in previous generations of compilers, web abstractions, etc.—demand for software keeps growing.
Models are better at coding earlier than almost anything else because coding is uniquely tractable: the data exists, you can containerize and run things in parallel, you can run unit tests and know when something works.
Self‑driving is uniquely hard because the car needs to work the first time. Coding is different: the model can fail a hundred times; as long as it succeeds once, it’s fine. There’s tractability and replayability that don’t exist when you directly touch the real world…You wouldn’t want an AI lawyer arguing your case in court right now
OpenAI alluded in a recent memo that such monolithic product market fit may be ultimately limiting for Anthropic, but Ben Thompson today made the point that may not be the case (emphasis mine):
I’m not sure I buy this, given that coding underlies so much of AI’s potential. A lot of AI products will ultimately be about applying coding in a seamless way to business problems without needing to know that coding is happening
The decision to focus on a use case that has the highest immediate return also can be key for keeping the questions on AI economics at bay. Jigar Doshi pointed out this week that even though AI revenues are exploding in each successive generation of models, the frontier window has been narrowing which kept the recovery of the costs uninspiring.
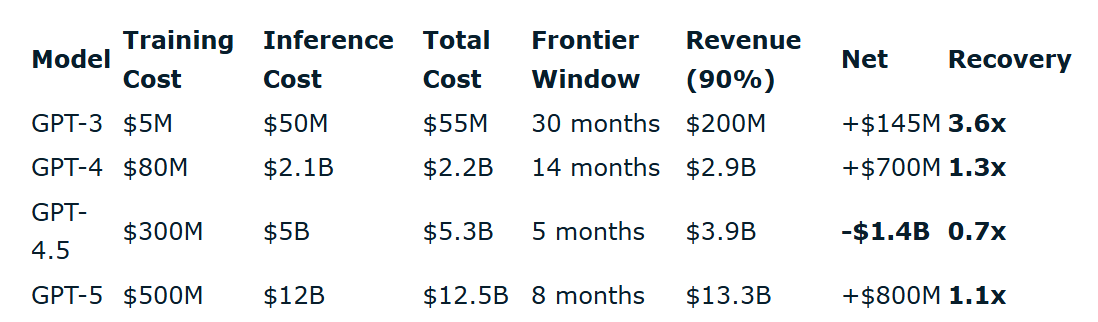
However, this may be no solace in the long-term if frontier models become increasingly more protective of their most advanced models to prevent distillation by competitors as well as use the model capabilities itself to build far more compelling first-party products. The frontier model developers may have some asymmetric advantage here. Again, from Jigar Doshi (emphasis mine):
“…labs and their strategic partners get first access to the strongest models, extract the highest-value discoveries, and then open the model to everyone else once the frontier has moved on. A startup using GPT-5 via API pays $5/$20 per million tokens. OpenAI's internal team pays inference at cost: same model, 10x the compute budget.”
A research agent doing genuine deep work might burn 50 million tokens to produce one insight; at external pricing that may be prohibitively expensive, but at internal cost the economics can be far more palatable. So the experiments that are economically possible internally for frontier model developers vs the ones done via API differ by category. Lab's internal R&D productivity is partially a function of having privileged access to its own frontier which can turn into a recursive advantage no API customer can replicate. In this scenario, app-layer companies aren't just one model generation behind, rather they're paying gross margins to the labs on compute the labs themselves get at cost, while being rate-limited out of the very techniques that produce the highest-value outputs. There is, of course, no free lunch. Every GPU-hour spent on internal research is one not spent serving paying API customers, so there’s a real opportunity cost the labs pay in foregone revenue if their internal research team doesn’t deliver compelling first-party products. But given the talent these labs are hiring, it may be a decent bet that the compute budget for internal teams is unlikely to be wasted. There are all sorts of hypotheses and speculation around why Anthropic may have held Mythos back from public release, but Zuckerberg’s point about frontier model’s availability via API in 4Q’25 call increasingly seems more prescient. From Zuckerberg:
“…my guess is that Frontier AI for many reasons, some competitive, some safety oriented are not going to always be available through an API to everyone. So I think like it’s very important, I think, to be able to have the capability to build the experiences that you want if you want to be one of the major companies in the world that helps to shape the future of these products. So that I think is -- it’s going to be, I think, important from a business perspective. And I think it’s just important from like a creative and mission perspective to be able to actually design and build the experiences that we believe that we should be building for people. But yes, I mean I think it’s quite important. Otherwise, we wouldn’t be so focused on this. We’re clearly extremely focused on this.”
Given that context, without frontier model capability what you can build can be fundamentally limiting if the players at the frontier becomes a monopoly. If OpenAI or Alphabet (or Meta) eventually gets closer to Mythos’ capability, Anthropic may be forced to release their model via API, but in case a monopoly arises in any particular capability, you can easily imagine the profits will start to flow…to the monopoly!
In addition to “Daily Dose” (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 67 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: