The Era of Tokenmaxxing
A couple of weeks ago, Meta’s internal dashboard for “tokenmaxxing” got a lot of attention after The Information reported on it. Although such tokenmaxxing phenomenon only started getting attention recently, Shopify has been doing something similar since mid-2025. It is also hardly a Meta or Shopify specific thing; Microsoft and Salesforce are also apparently following something similar.
In a recent podcast, Shopify’s CTO Mikhail Parakhin shared some interesting data on AI tool usage at Shopify. Perhaps the most interesting data point is nearly everyone on Shopify is using at least one of the AI tools daily. In the image below, the green line indicates the percentage of employees in Shopify who uses at least one AI tool daily. In early 2026, only half of Shopify employees used one of the AI tools daily. Today, this number is basically approaching 100%. Opus 4.5 was basically a gamechanger for adoption which has been driving the tokenmaxxing era in full speed.
Parakhin didn’t share exactly what each of the line below denotes to, but since he mentioned CLI-based tools are becoming more popular within Shopify, it’s probably fair to assume that the brown/tan line refers to Claude Code (Anthropic), and Orange to Codex (OpenAI) which are currently used by ~70% and ~55% of employees respectively on a daily basis in Shopify. Interestingly, he also indicated that tools that require IDEs such as GitHub Copilot, and Cursor are still growing but they’re losing share rapidly (red line in the image). Any Shopify employee can use any AI tool with unlimited token budget.
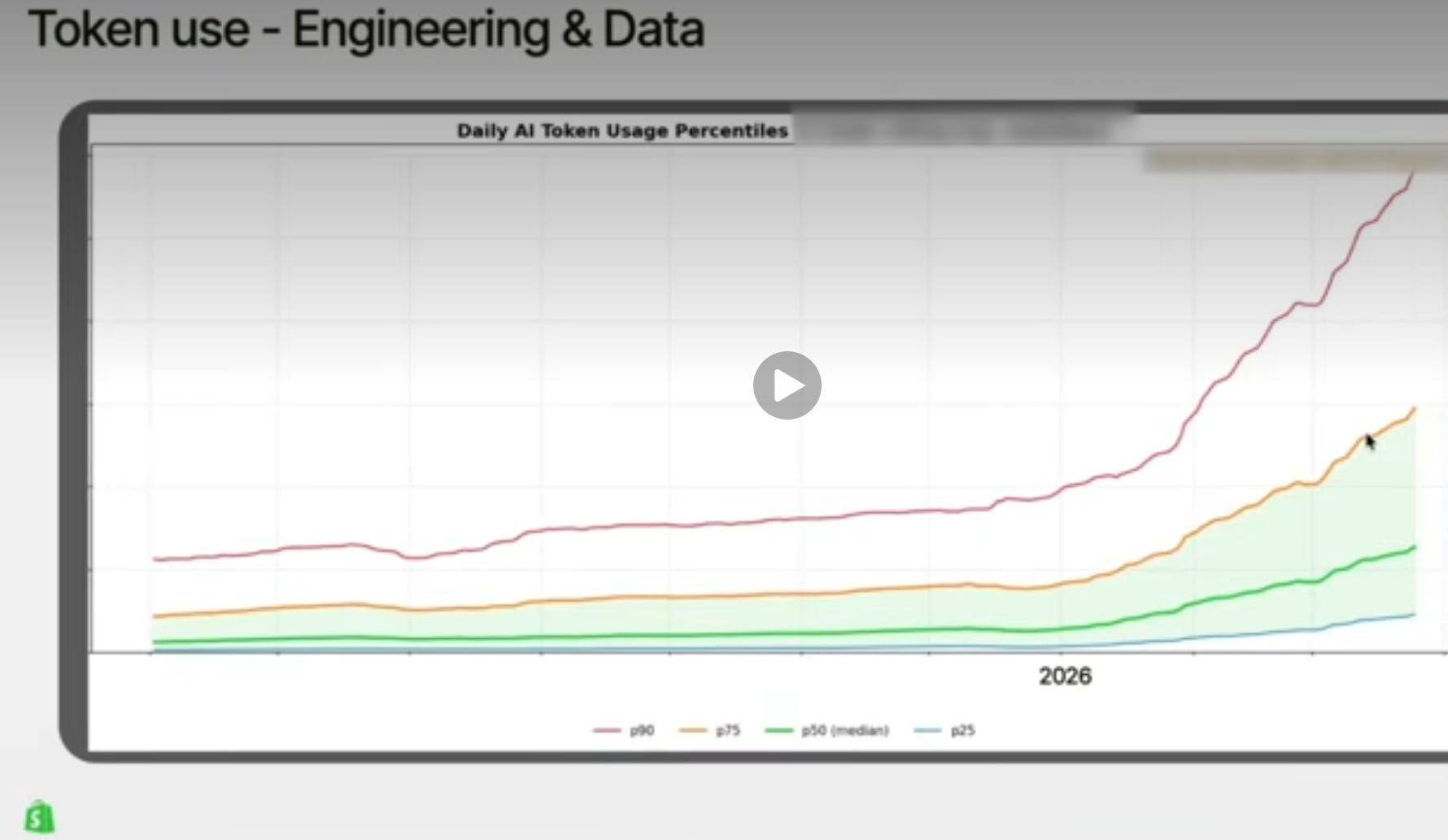
One interesting tidbit from the conversation is even though everyone is using AI tools on a daily basis, there is fair amount of inequality in usage. The top 10 percentile is actually growing significantly faster than the rest in Shopify and I suspect the trend is similar in other organizations. From the podcast:
the super interesting part here is that you could see that the distribution becoming more and more skewed.
The top percentiles grow faster. So that means- the people in the top ten percentile, their consumption grows faster than seventy-five and so forth. So, the distribution skews more and more towards the highest users, which is... I don’t know what it tells me. It’s like it feels not ideal, to be honest.
Looking at this data, I wondered if many tech companies will be forced to lay off the bottom 10 or 20 percentile token spenders to create budget for tokens for the top 10 or 20 percentile in the organization. Of course, the obvious retort to such tokenmaxxing trend is that it may fall into the trap of Goodhart’s law: "When a measure becomes a target, it ceases to be a good measure". I’m sure these tech companies know that and will look closely into the data to see whether higher token usage correlates highly to highly productive work and not some mindless token spending for the sake of it. And if the data suggests that top percentile users do highly productive work with higher token spending, more budget will naturally follow to them until it stops making sense.
There are at least two other reasons why tokenmaxxing may actually more sense than it may appear at first glance. The reality is tokens are likely still quite cheap; just yesterday, The Information reported that Cursor had negative 23% Gross Margin in 2025. While gross margins for Claude and Codex are likely lot better than that, I think token buyers should be able to pick a lot of long hanging fruit with such tools in the early stage of adoption of such tools. You can always optimize the costs later once you let everyone use these tools at their heart’s content for a few months and then look at the data closely to figure out the right optimization process later.
There is another interesting explanation why companies such as Meta whose models are not as good at coding as Claude Code or Codex are essentially using such wanton usage of token as a training data for their own model. The Pragmatic Engineer Newsletter mentioned this potential rationale (emphasis mine):
“Putting a leaderboard in place was always going to incentivize much more AI usage. And more AI usage means producing a lot more real-world traces. These traces can then be used to train Meta’s next-generation coding model better.
I believe this was the goal, even if no one said it out loud.
It’s an expensive way to generate data for training, but if any company has the means to do so, it’s Meta.”
Indeed, having a high quality training data perhaps also explains SpaceX’s deal with Cursor. Kevin Kwok articulated this rationale really well in this post (emphasis mine):
Cursor must train its own models. And they’ve done this, starting with post-training an open source model in Composer 1, then extended pre-training and post-training for Composer 2, and now beginning to pre-train their own models from scratch. But it is one thing to build budget models with better margins and another to compete head to head on the state of the art. The compute expense is in the billions–if you can even get the compute.
If Cursor believes it can compete at the highest levels but will see its position degrade without matching the AI labs on compute and model training, then Elon and SpaceX are their perfect complement.
Elon merged xAI into SpaceX. Since then, its research leadership has been entirely hollowed out. A morbid joke is that it’s been like Iranian leadership: every day a new head of research is battlefield promoted, and every next day they are gone.
In recent months Elon has become convinced of the importance of coding models, moving from a small team working on them to it being the entire lab’s priority. But building a coding model from scratch without any of the data or harness is hard to bootstrap. Even more so without research or product leadership.
xAI has tremendous compute capacity, with plans to scale it as much or more as any of the other labs. Everything datacenter-related says xAI should get stronger every year, but it is clearly underperforming that compute capacity. It has the cheapest cost of compute perhaps not just because it is so good at building datacenters but also because no one is using them. It has been a lab with neither product/research directions nor heads. And it is not converging on its competitors–it is falling behind.
Cursor is running out of time. xAI is in a race against time. Together they solve each other’s problems.
Cursor gives SpaceX the research and product leadership that has shown it knows how to build in this space. It’s not a sure thing, but no team outside of the labs or China has done more. And the product immediately solves xAI’s coldstart problems around data and harness. Meanwhile, SpaceX gives Cursor the compute to compete long-term on both model training and inference scaling.
Between them they have the complete loop. Neither does alone.
I have noticed many investors seem to be too eager to think the coding tool market is likely to be settled in a bit of a duopoly market between Claude Code and Codex. If that indeed turns out to be the case, future tokens may become quite expensive over time as such market structure may allow attractive margins for Claude Code and Codex. However, for a market that has only started couple of years ago, I suspect it is simply too early to declare winner(s) here. Anthropic was coding pilled more than any other labs, and as other labs are waking up to the extent of PMF coding tools have (and implication for such in the product downstream), I expect to see concerted effort from other labs to make this space more competitive. So, instead of coding market being settled to a monopoly or duopoly, we may actually be in the early stage of a more competitive market. As Gavin Baker pointed out, in the future you may be either token producer or token consumer and if you’re not a token producer, your ability to efficiently and effectively consume tokens as an organization may dictate your future. More competition, of course, would also be welcome if you are consuming tokens.
In addition to “Daily Dose” (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 67 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.