Token Cost Conundrums
A couple of weeks ago, I highlighted a couple of pieces by Anjali Shrivastava who made the point that a token is not a fixed unit of cost. Today’s piece is a follow-up driving the point home that even though every model charges its API customers per token, tokens are far from a standard unit.
Each model has its own tokenizer that decides how many tokens your prompt becomes. Feed the exact same prompt to GPT-5.4 and Claude Opus 4.7, and Claude might slice it into 2–3x as many pieces. So even if the headline price were exactly the same, you'd pay 2–3x more for identical content. It’s like two movers quoting you a rate per box. Mover A quotes you $10 per box but uses large boxes. On the other hand, Mover B charges you $8 per box, but uses small boxes. Mover B’s rate is 20% cheaper, but your apartment takes 10 boxes at Mover A and 18 at Mover B. As a result, the final bill turns out to be $100 vs. $144 i.e. the “cheaper” quote end up costing you 44% more. The key thing I want to highlight is Mover B wasn’t being dishonest with you; it was your job to understand the nuances of the quote and choose accordingly.
Instead of seeing texts as letters of words, a language model sees numbers. The tokenizer is the translator sitting at the door: you hand it English or code, and it hands the model back a sequence of numeric IDs. Every model has its own tokenizer with its own vocabulary, typically 50,000 to 250,000 “tokens.” Each token is a chunk of characters that got a dedicated ID. I asked Claude to explain this with an analogy:
“Think of a court stenographer. She has shortcut keystrokes for super common words — “the,” “court,” “objection” — each one keystroke. Uncommon words she has to spell out letter by letter. Her speed on any given trial depends entirely on how well her shortcut system matches the vocabulary of that case. A routine contract dispute flies by. A medical malpractice case full of “anastomosis” and “laparoscopic cholecystectomy” crawls, because those words aren’t in her shortcut set.”
Tokenizers work the same way, just learned from data. During training, the algorithm scans a huge pile of text and asks: which character sequences show up so often that they deserve their own token? Frequent stuff gets compressed e.g. “information” is probably one token, maybe two. However, rare stuff gets shattered i.e. an obscure chemical name might take eight tokens, one per syllable or letter cluster. Tokenization is essentially a compression algorithm, and compression inherently only works on patterns you’ve seen before.
These all may seem unnecessary details, but after reading a recent piece on TensorZero, I appreciated how these details can have a material impact on how much the customers are paying to the model developers. Some excerpt from TensorZero:
“We sent identical inputs through each provider’s official token counting API and normalized against OpenAI’s:
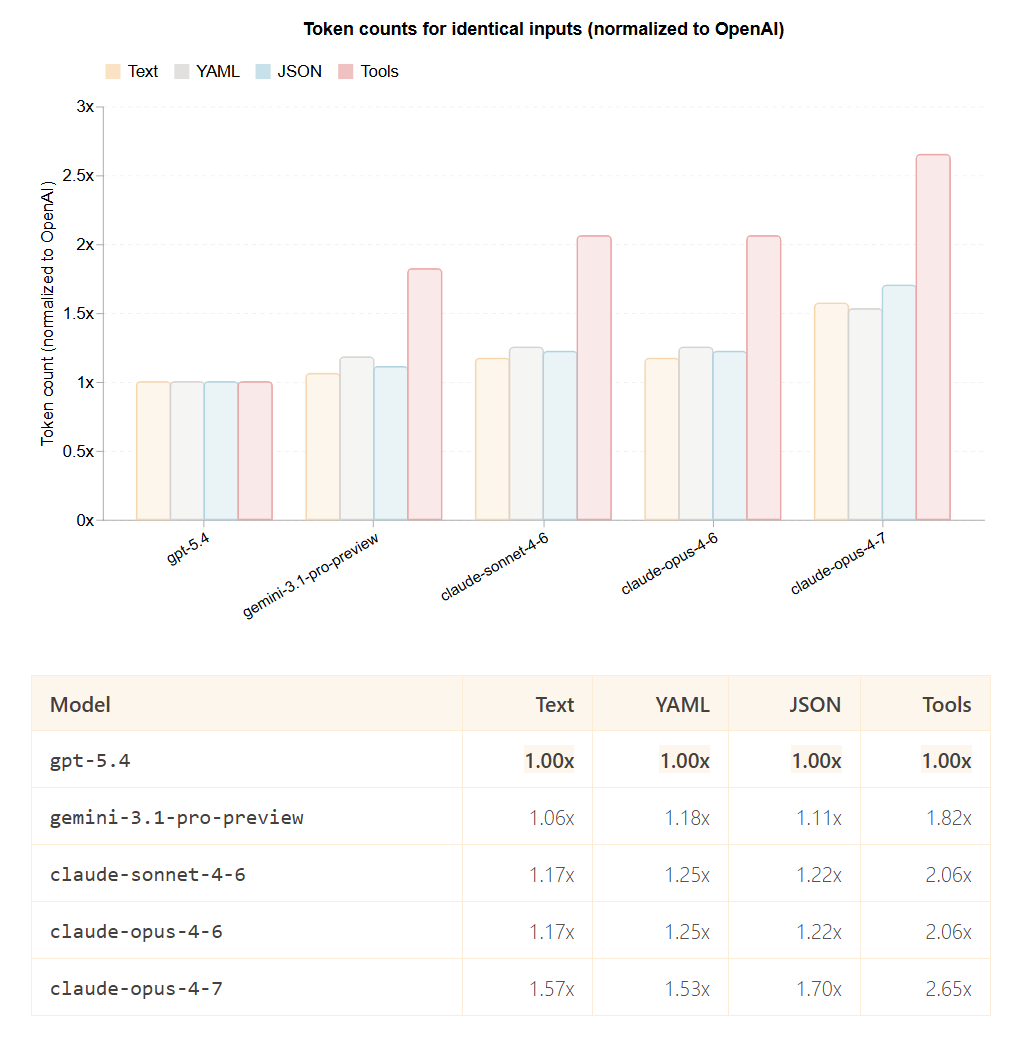
Multiplying list price by tokenizer efficiency gives you what you actually pay to process the same input.
The differences are dramatic. On tool-heavy workloads, claude-opus-4-7 costs 5.3x more than gpt-5.4 even though their list prices are only 2x apart. The rankings also flip depending on what you’re sending: Gemini is the cheapest option for text and structured data, but becomes 46% more expensive than OpenAI on tool definitions.
The only way to know what you’re actually paying is to measure it.”
As you can see, tokenization is a non-transparent billing unit that each vendor controls unilaterally. If a provider bills for hidden reasoning or other opaque internal operations, the customer may be paying for a large share of compute they cannot directly observe or verify. Remember what I said before: the mover wasn’t being dishonest (okay fair, you can probably say they were being clever) to quote you a cheaper price but using a smaller box; it was your job to figure out the difference in box dimension and other details before hiring the mover.
Similarly, after understanding these nuances, I think any enterprise would be really imprudent to standardize on just one model developer. This is because the customer loses bargaining power, a benchmark, and the ability to distinguish real quality differences from billing artifacts. If the seller controls both the meter and the service, and the buyer has no parallel benchmark, the buyer is highly likely to end up paying more over the long term. Even if the model developer isn’t sneakily charging you higher price, without any benchmark, how will the customer press the model developer to lower their price or even understand that they’re paying too high a price?
I have gone through a couple of papers on Arxiv which laid out these concerns as well. Here’s one paper pointing out the asymmetry of information between the model developers and customers:
“Our key observation is that, in the interaction between a user and a provider, there is an asymmetry of information. The provider observes the entire generative process used by the model to generate an output, including its intermediate steps and the final output tokens, whereas the user only observes and pays for the (output) tokens shared with them by the provider. This asymmetry sets the stage for a situation known in economics as moral hazard, where one party (the provider) has the opportunity to take actions that are not observable by the other party (the user) to maximize their own utility at the expense of the other party.
The core of the problem lies in the fact that the tokenization of a string is not unique. For example, consider that the user submits the prompt “What is the oldest city in the world?” to the provider, the provider feeds it into an LLM, and the model generates the output “|Dam|ascus|” consisting of two tokens. Since the user is oblivious to the generative process, a self-serving provider has the capacity to misreport the tokenization of the output to the user without even changing the underlying string. For instance, the provider could simply claim that the LLM generated the tokenization “|D|a|m|a|s|c|u|s|” and overcharge the user for eight tokens instead of two!”
Another paper also highlighted the point that pricing variation can be quite arbitrary:
“We find empirical evidence that, particularly for non-english outputs, both proprietary and open-weights LLMs often generate the same (output) string with multiple different tokenizations, even under the same input prompt, and this in turn leads to arbitrary price variation.”
Even though it may be prudent to no standardize on one model, I do wonder whether the gravitational pull of standardization will be too much to ignore. Enterprises may standardize on a model because they've written prompts against its quirks, built evals around its output style, fine-tuned retrieval to its context window, and trained their engineers on its API. The cost of rewriting a production AI stack for many enterprise customers may be so high that even if they knew Anthropic's tokenizer was less efficient than GPT's, they might rationally stay with Anthropic. I’ll go back to what Dario Amodei said why he thinks API business will be much more sticky than some might think:
Dario Amodei:
So often I’ll talk about the platform and the importance of the models. For some reason, sometimes people think of the API business and they say, “Oh, it’s not very sticky.” Or, “It’s going to be commoditized.”
John Collison:
I run an API business. I love API businesses.
Dario Amodei:
No, no, exactly, exactly. And there are even bigger ones than both of ours. I would point to the clouds again. Those are $100 billion API businesses, and when the cost of capital is high and there are only a few players... And relative to cloud, the thing we make is much more differentiated, right? These models have different personalities, they’re like talking to different people. A joke I often make is, if I’m sitting in a room with ten people, does that mean I’ve been commoditized?
John Collison:
Yes, yes, yes.
Dario Amodei:
There’s like nine other people in the room who have a similar brain to me, they’re about the same height, so who needs me? But we all know that human labor doesn’t work that way. And so I feel the same way about this
…we’re like one of the biggest customers of the clouds, and we use more than one of them. And I can tell you, the clouds are much less differentiated than the AI models
Nonetheless, the smart move does seem to be multi-model capability (even if 95% of volume goes to one vendor) plus internal benchmarks run on your actual prompts. That gives you the optionality to switch and more importantly, the negotiating leverage to push back at contract renewal. Given this context, I believe it will be exceptionally unlikely that enterprise AI will ever be dominated by one model developer. Anthropic may be dominating enterprise AI today, but OpenAI and Google will also likely have plenty of opportunities to gain further ground.
In addition to “Daily Dose” (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 67 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: