The ROI Question
A friend recently DM-ed me to highlight one of the quotes from Nvidia’s CFO in their recent earnings: "New NVFP4 4-bit precision and NVLink 72 on the GB300 platform delivers a 50x increase in energy efficiency per token compared to Hopper, enabling companies to monetize their compute at unprecedented scale. For instance, a $3 million investment in GB200 infrastructure can generate $30 million in token revenue, a 10x return."
10x return? That’s a bit eye-popping number. My friend was understandably a bit skeptical of this claim, so he asked ChatGPT to show the math and some reasonable assumptions behind this claim. He then shared couple of screenshots from his ChatGPT which are shown below:


Why was my friend a bit skeptical? Well, clearly hyperscalers aren’t realizing such revenue from their investments in Nvidia chips yet. He also pointed out since a material percentage of chips are going to train the models, this math isn’t quite relevant yet but we both agreed that it does show latent monetization potential of their massive capex investments once supermajority of the capex shifts from training to inference.
Looking at the math, I myself wanted to gain a bit deeper understanding of the drivers of the assumptions here. So I chatted with both ChatGPT and Gemini for almost a couple of hours yesterday; let me summarize my understanding based on these chats to discuss the three key variables in the ROI question: Token per second, utilization, and price per token.
Token/sec or throughput
Batch size, which is the number of concurrent user requests processed simultaneously, is the single most important operational factor for maximizing throughput. The highest throughput numbers are always achieved with the largest possible batch sizes.
However, large batch sizes increase latency, specifically the Time-to-First-Token (TTFT). The system must wait to assemble a large batch before processing begins. For interactive applications (chatbots, real-time coding assistants), a high TTFT is understandably unacceptable. To maintain low latency, providers must deliberately use smaller batch sizes. This inherently sacrifices aggregate throughput to ensure a good user experience. The 1M tokens/sec benchmark mentioned in the ChatGPT screenshot above is likely achieved at latencies that would be unacceptable for real-time use.
Efficient batching works best when requests are similar. If one request asks for 10 tokens and the next asks for 2,000 tokens, the batching mechanism becomes inefficient, as resources may be tied up waiting for the longest request to complete.
Moreover, some models support increasingly large context windows (100k+ tokens). Processing these long contexts significantly degrades throughput. The longer the context, the larger the KV cache (a memory optimization that speeds up AI text generation by storing past calculations, allowing the model to focus only on generating the next word instead of reprocessing the entire conversation history each time) required to store that context in GPU memory.
Utilization
While 20% utilization may seem conservative, achieving this average utilization consistently (24/7/365) with monetized workloads may not be super easy in inference. AI inference demand is often "peaky." Infrastructure built for peak load sits idle during off-hours. We also need to consider time lost to maintenance, updates, and optimization. Of course, in the long run, when AI is diffused across different industries throughout the world, we should expect to see a materially high utilization. The argument of “peaky” infrastructure requirement reminds me of skepticism around cloud, but we know with enough diversity around end market demands, this can be solvable and utilization can be maintained at a pretty high level.
Token price
Competition among major providers and the rise of capable open-source models have driven down token prices significantly in the last couple of years. However, as I noted recently, token price seems to have stabilized a bit in recent months.
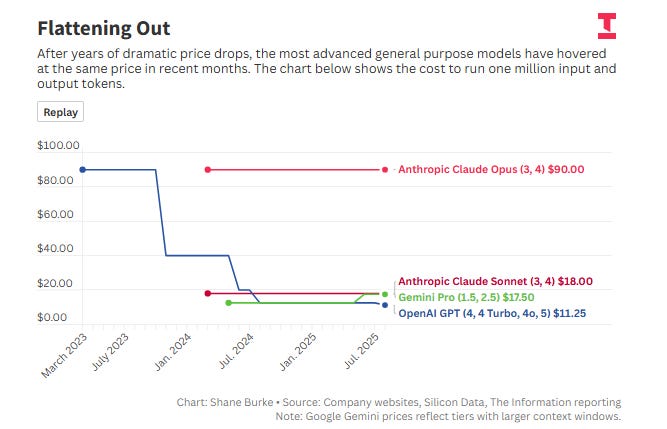
However, the GB200 itself can accelerate token price decline. By making inference vastly more efficient and increasing the supply of compute, it may force providers to lower prices to remain competitive. Of course, hyperscalers do not only run the most expensive models. A likely material portion of their workload involves smaller, cheaper models (often <$1 per 1M tokens), reducing the actual blended revenue shown in my screenshot above. If the average realized price drops to $2/M tokens, the idealized revenue drops from $31.5M to $12.6M in my example (ceteris paribus).
Nvidia is clearly not stopping anytime soon either. If a new architecture doubles performance in two years, the older GB200 hardware will no longer be able to command premium pricing. So, pricing can be quite dynamic.
Overall, the whole exercise gave me a slightly better sense around sensitivity of different variables to realize ROI on these massive capex investments by big tech. The question on ROI is obviously far from solved especially if a material percentage of incremental capex continues to go for training the next model, but you can perhaps appreciate a bit more why it is such a good debate. It is a much closer debate than perhaps both the bulls and bears like to think.
In addition to "Daily Dose" (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 62 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: