Meta's Chip Resilience
AWS, Google, and Microsoft have all deployed a similar chip strategy with varying degree of success. Google has its TPUs, AWS has Trainium, and Microsoft has its Maia chips. The success of their chips so far are also in that order with TPU being ahead of the pack and Maia being the clear laggard. All three, of course, also buy massive amounts of Nvidia hardware.
However, the fate of their in-house chips in 3P cloud workloads can be heavily constrained by their cloud customers. Since the vast majority of external AI developers rely on Nvidia’s proprietary software platform CUDA, hyperscalers’ customers can continue to have a strong preference for Nvidia chips. Even if AWS or Azure builds a cheaper, highly efficient custom AI chip, their external customers overwhelmingly may demand Nvidia hardware. As a result, the cloud hyperscalers may be essentially forced to buy Nvidia GPUs at whatever price Nvidia dictates, or risk losing those enterprise customers to a rival cloud.
Meta is entirely immune to this customer-driven vendor lock-in, making its multi-vendor approach significantly more resilient to supply chain shocks and pricing leverage. Meta can legitimately pit Nvidia, AMD, and its own MTIA foundries against one another to secure the absolute lowest prices and best supply allocations, whereas cloud providers are largely price-takers in the Nvidia ecosystem. I came to this realization after reading my friend Liberty’s thoughts on this topic:
The major hyperscalers (Google, AWS, Microsoft) are in at least a partial conflict of interest. They build chips, but they also have to sell cloud space to external developers who often demand the ‘industry standard’ (Nvidia), or are locked into a certain stack by legacy decisions.
They have to offer a full menu, or they may lose customers.
Meta, however, is its own customer. They use compute to do 1st party workloads like recommend Insta Reels, moderate crazy-uncle comments on Facebook, and serve ads.
Because it doesn’t have to convince external buyers of anything and has full control over their stack, they can pivot to AMD or TPUs or their own custom silicon the second the math (TCO) makes sense.
Meta can more easily move $10B of capex from Nvidia to AMD than the cloud vendors, because they don’t need the Nvidia brand name to sell cloud services to third parties.
This makes them the ultimate “swing voter” in the semiconductor market.
Meta is simultaneously committed to a multi-year Nvidia deal covering Blackwell and next-gen Rubin GPUs, has signed a 6GW AMD deal for custom MI450 silicon, is developing its own MTIA chips, and is reportedly exploring TPU access from Google. That’s the compute-agnosticism thesis playing out in real time, not just in theory.
As Liberty mentioned, Meta’s custom-built silicon is explicitly designed to run the company's most predictable, high-volume internal tasks: the ranking and recommendation algorithms that decide which ads, Reels, and posts show up on your Facebook and Instagram. Meta recently announced an aggressive roadmap to roll out four new generations of these chips (MTIA 300, 400, 450, and 500) through 2027. A Blog post by Meta yesterday elaborated their philosophy on in-house chips. Some key excerpts from Meta’s blog post (all emphasis mine):
“As our current AI workloads continue to grow and evolve, we’re taking a portfolio approach to scale our infrastructure capacity by sourcing silicon from a range of industry leaders, while keeping our own MTIA custom silicon at the center of our AI infrastructure strategy.
We deploy hundreds of thousands of MTIA chips for inference workloads across both organic content and ads on our apps. These chips are specifically designed for our workloads, and are part of a custom full-stack solution, helping us create a highly optimized system that’s tailored to our needs. This system achieves greater compute efficiency than general use chips for our intended purposes, making MTIA much more cost efficient.
While the industry typically launches a new AI chip every one to two years, we’ve developed the capacity to release ours every six months or less by building on our modular, reusable designs. This accelerated pace enables us to quickly adapt to evolving AI techniques, adopt the latest hardware technologies, and minimize costs associated with developing and deploying new chip generations.
Mainstream chips are typically built for the most demanding workload — large-scale GenAI pre-training — and then applied, often less cost-effectively, to other workloads like GenAI inference. We take the opposite approach: MTIA 450 and 500 are optimized first for GenAI inference, and they can then be used to support other workloads as needed, including ranking and recommendations training and inference, as well as GenAI training. This keeps MTIA well-tuned to the anticipated growth in GenAI inference demand.
There is no single chip that can meet all the demands across our varying needs, which is why we’re working to deploy a variety of chips that are optimized for each of our different workloads. We believe our portfolio approach will enable us to advance and innovate at an unmatched pace, bringing us closer to our goal of creating personal superintelligence for all.”
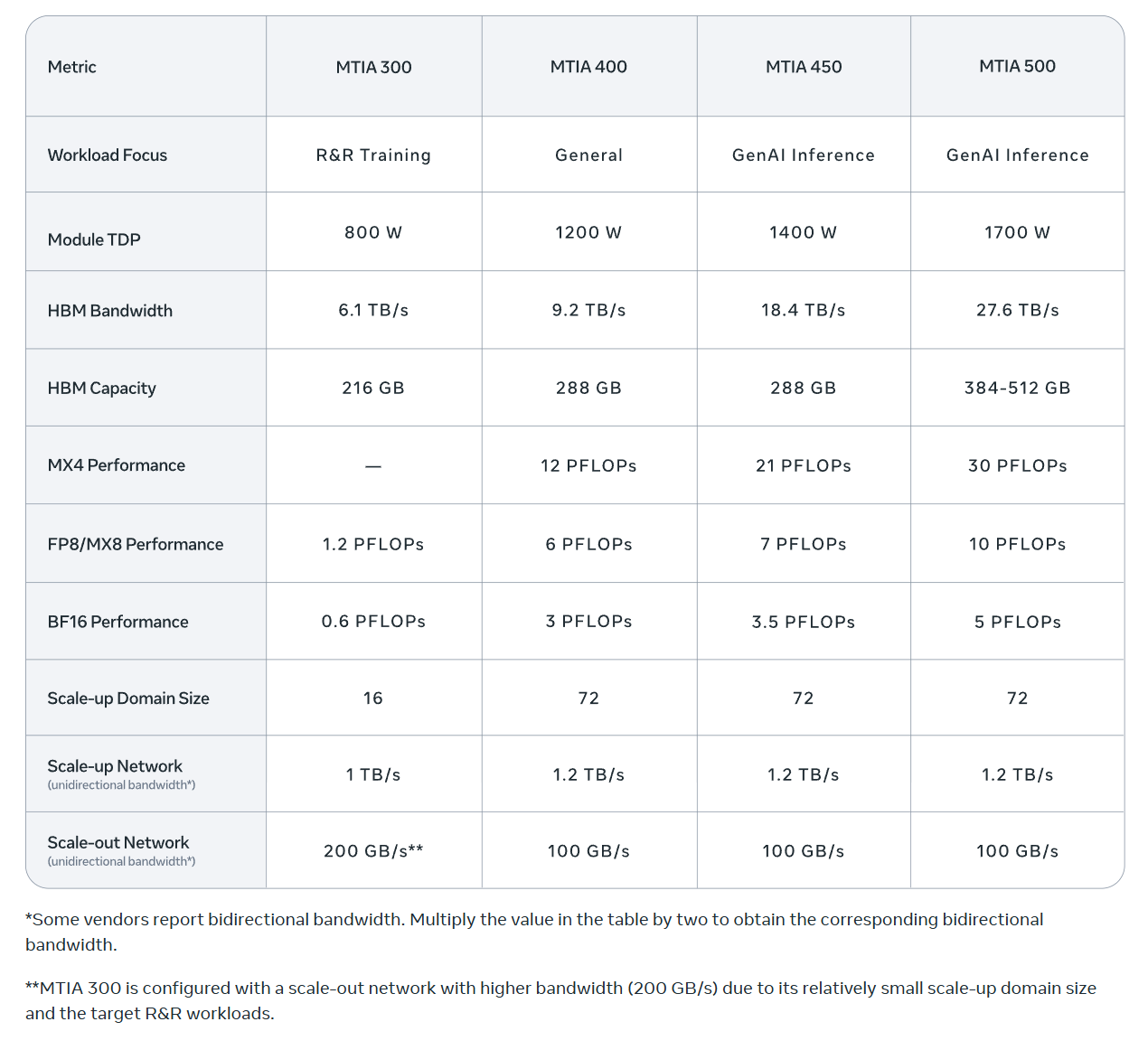
While Meta’s approach is operationally superior, it’s not all puppies and kittens for Meta. There are indeed some trade-offs here. The other hyperscalers can, of course, amortize the cost of building these in-house chips over larger number of customers and workloads, and given their relative diversity of customer base, they’re not putting all the eggs on the advertising basket. Perhaps more importantly, in an earlier blog post last year, Meta’s own engineers mentioned dealing with 5–6 hardware SKUs a year makes it harder to move workloads around and can create underutilization and software friction. From Meta’s own blog post last year (emphasis mine):
“From an operator point of view, it is difficult for Meta to deal with 5-6 different SKUs of hardware deployed every year. Heterogeneity of the fleet makes it difficult to move workloads around, leading to underutilized hardware. It is difficult for software engineers to think about building and optimizing workloads for different types of hardware. If new hardware necessitates the rewriting of libraries, kernels, and applications, then there will be strong resistance to adoption of new hardware. In fact, the current state of affairs is making it hard for hardware companies to design products because it is difficult to know what data center, rack, or power specifications to build for.”
So while this portfolio approach creates incredible resilience in Meta’s chip strategy, there is predictably no free lunch.
In addition to “Daily Dose” (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 66 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: