Golden age of Digital Ads, LLM P&L
Golden age of Digital Ads
Last month, some researchers at Meta published a very interesting paper that highlighted Meta’s ability to monetize LLMs through its core advertising platform. Meta management sort of alluded to some of these during earnings calls, but this paper really drove the point home for me.
Meta has a feature named “Text Generation” in their Ads Manager tool. The Text Generation tool helps advertisers put in their own ad text i.e. their original idea, and then the LLM behind it suggests several different variations of that texts (see the figure below). You can think of it as a brainstorming partner for the advertiser but the advertiser retained full control. They could use it for inspiration, edit heavily, or just stick with their own original text.
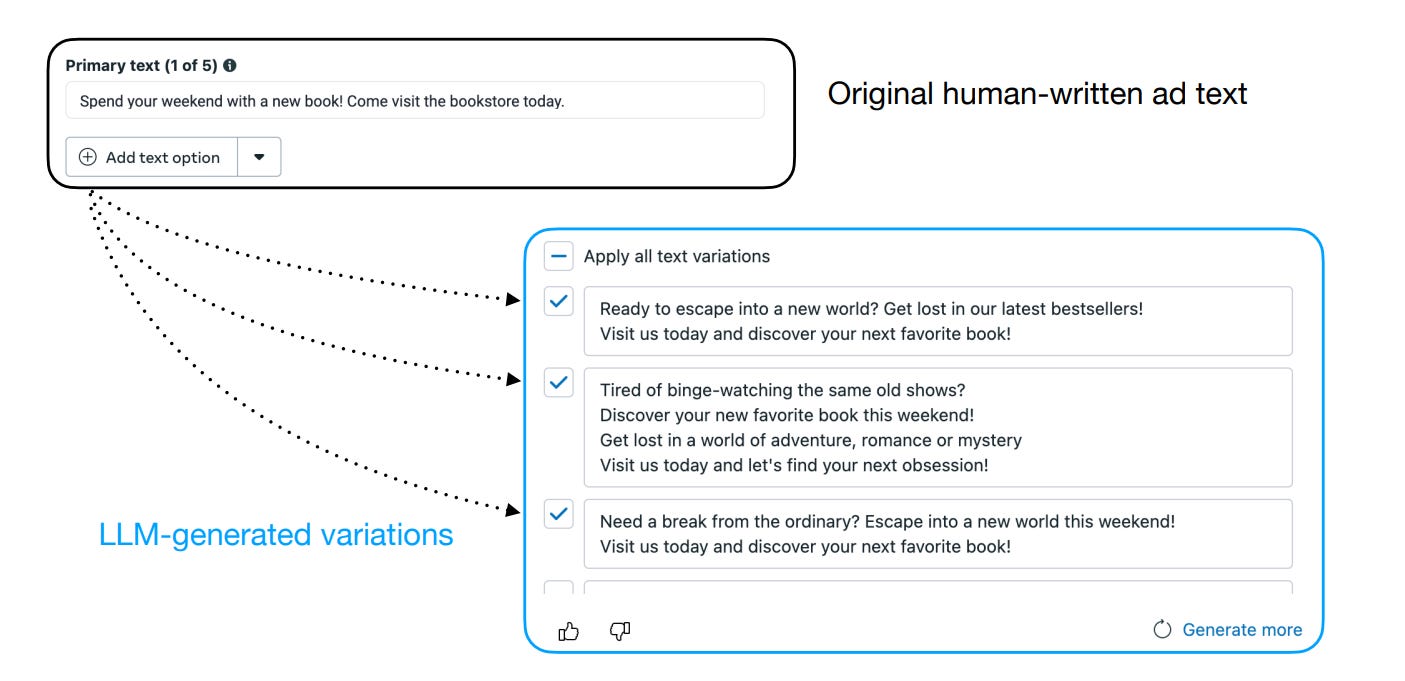
This paper talks about Reinforcement Learning with Performance Feedback, or RLPF, and a model called AdLlama. Instead of imitating how people write, the system optimizes for what people do. Unlike writing a poem or something subjective, ad text effectiveness can be tied to something very concrete and measurable: click-through rate or CTR which is basically clicks divided by impressions. It's a direct and quantifiable measure of engagement, so no opinion needed.
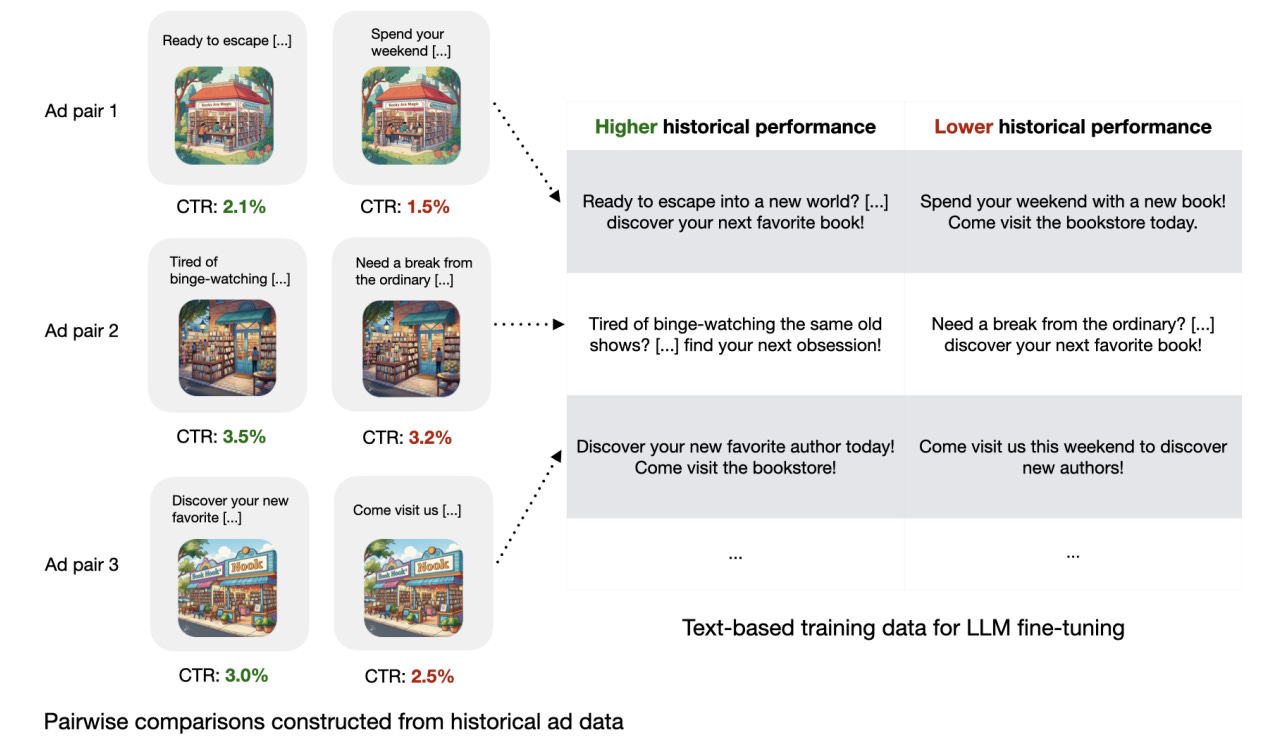
The paper talks about a two-step process. First, they train something called a performance reward model. This model's job is to predict the CTR of any given piece of ad text based purely on historical data. They used loads of past ad data, where the only difference between ads shown to similar audiences was the text itself. This let them create pairs. This text got a higher CTR than that text, so they could directly compare text performance. See the below diagram to get a sense of the tests.
Feeding millions of these comparisons into the reward model teaches it to score ad text based on its likely click performance. Think of it like millions of Facebook users voting with their clicks over time.
Then step two, they use this reward model to fine-tune the base LLM, which was Llama 2 Chat 7B in this case. The goal is to adjust the LLM so that it becomes more likely to generate text that the reward model gives a high score to. So, it's actively trending to write text that will get more clicks based on what the reward model learned from real user behavior.
They ran a big A/B test on Facebook. The test ran for 10 weeks early 2024, and involved almost 35k advertisers and generated ~640k ad variations. Advertisers were randomly split. Half got the old system, the Imitation LLM V2. That was the control group. The other half got the new system, AdLlama, trained with RLPF, the test group.
The main result was a statistically significant 6.7% increase in CTR for the advertisers using AdLlama compared to the ones using the old imitation model. Getting 6.7% gain in CTR on a platform of Meta’s size, especially that's already so highly optimized is pretty impressive.
More importantly, they found AdLlama increased the total clicks per advertiser, but didn't just do it by showing ads more often. The total impressions weren't affected. The ads themselves were just genuinely more effective at getting clicks.
Moreover, they found advertisers using AdLlama actually generated 18.5% more ad variations which likely indicates the advertisers found the outputs more useful and more aligned with their goals. So they were more willing to adopt them and create more versions for their campaigns.
How much improvement is still possible? Well, the theoretical limit for CTR is 100%! Joking aside, it’s certainly possible for further optimization as model quality improves over time. I will again highlight some key excerpts by Zuck from Meta’s recent earnings call:
“we're seeing with teams internally being able to adapt Llama 4 to build autonomous AI agents that can help improve the Facebook algorithm to increase quality and engagement are like -- I mean, that's like a fairly profound thing if you think about it. I mean it's happening in low volume right now. So I'm not sure that, that result by itself was a major contributor to this quarter's earnings or anything like that. But I think the trajectory on this stuff is very optimistic.
I think that for developing superintelligence, at some level, you're not just going to be learning from people because you're trying to build something that is fundamentally smarter than people. So it's going to need to learn how to -- or you're going to need to develop a way for it to be able to improve itself.
So that, I think, is a very fundamental thing. That is going to have a very broad implications for how we build products, how we run the company, new things that we can invent, new discoveries that can be made, society more broadly. I think that that's just a very fundamental part of this.”
Of course, this is not a Meta specific innovation. I expect almost all digital advertisers to benefit from this, and the ad dollars will likely accelerate from other channels to digital ad platforms.
Beyond the ad platforms, the paper hinted at some broader implications which I found to be quite interesting. The core principle of RLPF, using real-world performance metrics to train the AI, could apply anywhere you have language linked to some kind of measurable outcome. From the paper:
“The ability to generate more engaging ad content not only improves existing advertisers’ return on investment, but could also lower the barrier to entry for new and inexperienced advertisers (e.g., small businesses) by reducing the need for extensive marketing expertise and resources.
…the principles of RLPF can be adapted to other domains where aggregate performance metrics are available. By using performance data as a feedback mechanism, organizations can fine-tune LLMs to optimize for their desired outcomes. For example, the core methodology can easily be extended to closely related settings like personalized email campaigns or e-commerce product descriptions. RLPF can also be extended to settings with multiple rounds of interactive feedback, such as AI customer support agents, using metrics like resolution rates, satisfaction scores, or user response times. There are also less obvious settings where RLPF could be applied. For example, in online learning platforms, student performance data (test scores and engagement metrics) could guide the generation of adaptive learning content, while for certain public awareness campaigns (e.g., vaccination, energy consumption), performance data could enable LLMs to rewrite communication materials to better resonate with their intended audience.”
LLM P&L
Stripe Co-founder John Collison recently interviewed Anthropic Co-founder Dario Amodei. It’s an interesting interview, and I recommend listening/watching. There were quite a few quotable sections but I found the below excerpt particularly interesting:
John Collison:
I would love to understand how the model business works, where you invest a bunch of money up front in training, and then you have this fast-ish depreciating assets, though maybe with a long tail of usefulness, and hopefully you pay that back. Thus far, I think the image people have from the outside world is ever larger amounts of CapEx, and how does all that—
Dario Amodei:
Get kind of burned. There's two different ways you could describe what's happening in the model business right now. So, let's say in 2023, you train a model that costs $100 million, and then you deploy it in 2024, and it makes $200 million of revenue. Meanwhile, because of the scaling laws, in 2024, you also train a model that costs $1 billion. And then in 2025, you get $2 billion of revenue from that $1 billion, and you've spent $10 billion to train the model.
So, if you look in a conventional way at the profit and loss of the company, you've lost $100 million the first year, you've lost $800 million the second year, and you've lost $8 billion in the third year, so it looks like it's getting worse and worse. If you consider each model to be a company, the model that was trained in 2023 was profitable. You paid $100 million, and then it made $200 million of revenue. There's some cost to inference with the model, but let's just assume, in this cartoonish cartoon example, that even if you add those two up, you're kind of in a good state. So, if every model was a company, the model, in this example, is actually profitable.
What's going on is that at the same time as you're reaping the benefits from one company, you're founding another company that's much more expensive and requires much more upfront R&D investment. And so the way that it's going to shake out is this will keep going up until the numbers go very large and the models can't get larger, and then it'll be a large, very profitable business, or, at some point, the models will stop getting better, right? The march to AGI will be halted for some reason, and then perhaps it'll be some overhang. So, there'll be a one-time, "Oh man, we spent a lot of money and we didn't get anything for it." And then the business returns to whatever scale it was at.
Maybe another way to describe it is the usual pattern of venture-backed investment, which is that things cost a lot and then you start making it, is kind of happening over and over again in this field within the same companies. And so we're on the exponential now. At some point, we'll reach equilibrium. The only relevant questions are, at how large a scale do we reach equilibrium, and is there ever an overshoot?
It’s always tricky to take such excerpts literally especially in a free flowing conversational format such as podcast, but part of me wonders whether Amodei was particularly generous in his assumptions about profitability by model cohorts (who knows!). More importantly, model developers enjoy far from a monopolistic market today which can push price per token down faster than cost per token. Frankly speaking, when I observe each part of the chips or even cloud value chain, model developers seem to operate under far more competitive intensity than anyone else. The entire chip value chain is dominated by a bunch of monopolies or duopolies. Hyperscalers such as Google are much more vertically integrated than any other SOTA model developers. So, even when we do reach the equilibrium, I’m not sure we can be so confident that SOTA model developers will just be able to pull the trigger and start milking the “final model run” for eternity. It could even be the opposite. Once competitors realize the “final model” has been run and it’s time to focus on efficiency and deep optimizations, I have hard time believing an amicable outcome for every surviving SOTA model developers.
Amodei did point out that he believes models are much more differentiated than hyperscalers, so presumably if hyperscalers can generate ~20-40% operating margin, SOTA model developers should be just fine. From the podcast:
Dario Amodei:
So often I'll talk about the platform and the importance of the models. For some reason, sometimes people think of the API business and they say, "Oh, it's not very sticky." Or, "It's going to be commoditized."
John Collison:
I run an API business. I love API businesses.
Dario Amodei:
No, no, exactly, exactly. And there are even bigger ones than both of ours. I would point to the clouds again. Those are $100 billion API businesses, and when the cost of capital is high and there are only a few players... And relative to cloud, the thing we make is much more differentiated, right? These models have different personalities, they're like talking to different people. A joke I often make is, if I'm sitting in a room with ten people, does that mean I've been commoditized?
John Collison:
Yes, yes, yes.
Dario Amodei:
There's like nine other people in the room who have a similar brain to me, they're about the same height, so who needs me? But we all know that human labor doesn't work that way. And so I feel the same way about this
…we're like one of the biggest customers of the clouds, and we use more than one of them. And I can tell you, the clouds are much less differentiated than the AI models
These are interesting point of views, but I’m not sure I fully buy it. Cloud lock‑in comes from data gravity, IAM/policy, networking, compliance, and dozens of interdependent managed services. “Model personality” may be more of a durable differentiator in consumer use cases, but I’m less convinced when it comes to enterprise use cases where the decision makers may not necessarily be actual end users, especially when we may be talking about billions of dollars in API bills.
In addition to "Daily Dose" (yes, DAILY) like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 61 Deep Dives here.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.
My current portfolio is disclosed below: