MBI Daily Dose (July 12, 2025)
Companies or topics mentioned in today's Daily Dose: Stripe, Google, Meta, The Wealth Ladder
Emily Glassberg Sands, Stripe’s Head of Information, had an interesting podcast recently. She explained why Stripe has been building a foundation model.
Stripe's massive volume of payment data is a unique asset, different from the data used to train language or image models. At this immense scale, however, the financial data begins to show language-like patterns, allowing them to apply similar AI techniques to learn the complex relationships and semantics between transactions.
Later in the podcast, she gave a specific example where foundation models can be more useful than traditional ML models. Imagine a fraudster tests a list of stolen credit card numbers with very small transactions to see which ones are still active. The goal is to either use the working cards for larger thefts later or sell the validated list to other fraudsters.
Traditionally, fraud detection systems struggled with this. A fraudster could hide a few hundred tiny, seemingly insignificant purchases (like for less than $1) within a sea of hundreds of thousands of legitimate transactions on a large retail website. For the older models, this fraudulent activity was too scattered and small to be noticed; it was lost in the noise. However, the new "foundation model" operates differently. Instead of looking at each transaction in isolation, it analyzes the sequence and pattern of events over time. It can recognize that hundreds of nearly identical, low-value requests perhaps coming from slightly different IP addresses but at regular intervals are related. This whole group of suspicious activities is flagged as a potential card testing attack.
The key advantage is that you only need a small amount of evidence to confirm that the entire cluster of activity is fraudulent. Once the pattern is identified as an attack, the whole group of transactions can be blocked. By combining this new pattern-seeking approach with their existing models, Stripe was able to improve its detection rate for this type of fraud on major merchants from 59% to an impressive 97%.
We are perhaps still in the early stages of exploring all the potential applications of LLMs in all sorts of industries. I use Stripe to process payments at MBI Deep Dives, and I can sense it would actually be quite useful to be able to “chat” with a bot instead of clicking around to find certain things within their platform.
In addition to "Daily Dose" like this, MBI Deep Dives publishes one Deep Dive on a publicly listed company every month. You can find all the 60 Deep Dives here. I would greatly appreciate if you share MBI content with anyone who might find it useful!
I have been listening to Acquired’s recent episode on Google for the last couple of days. It’s a three and half hour marathon and they will probably need to do another six hours of podcast to get to 2025 since they ended the first episode of the series in mid-2000s. If you listened to any of the Acquired’s episodes, they have a lot of interesting nuggets.
It was striking how incredibly aggressive the early days of Google were. The moment they understood scale and distribution is of paramount importance in search, they were almost willing to move mountains. This is not quite a novel insight, but still useful to internalize how Ben explained search is an amazing “increasing-returns-to scale” type business:

One of the things that stood out from the episode was how luck played such a role in Google’s formation. My sense is Page and Brin would probably end up being billionaires anyway even if they didn’t start Google (they would probably just found something else), but they were indeed likely lucky to start Google which ended up being the most profitable company in the US in less than three decades after its founding.
David mentioned if the Google boys tried to start a company a few years earlier than Google, they would probably end up building a portal (i.e. Yahoo) since the internet was just too small to require a search engine. But if they tried this a couple years later, they might not have done it because it would take too much capital to test their idea being a grad student at Stanford.
Another funny bit is Google actually had very little idea about their business model and their first attempt was to sell the search technology to enterprise customers. I guess consumer is just so hard that even entrepreneurs don’t consider it a viable path; you need bit of a lightning on a bottle moment to think that’s a feasible path.
Of course, the future of the most profitable business in earth is now under the scanner these days. But like I said, they have only covered up to mid-2000s so far. They will get to AI et al in the later episode(s).
Semianalysis shared some thoughts on Meta’s newly formed Superintelligence team. The piece had good context around Meta’s challenges in Llama 4 and Meta’s aggressive plan for building datacenters. While I think Zuck’s strategy here is right, it is still disappointing to see Meta trying to be on catch up mode, especially when Zuck was so early in understanding AI is a big deal!
From Semianalysis:
Mark Zuckerberg understands the talent gap relative to leading AI labs and has taken over recruiting. He’s on a mission to build a small but extremely talent-dense team, casually offering signing bonuses in the tens of millions of dollars. The goal is to create a “flywheel effect”: top tier researchers join the adventure, bringing credibility and momentum to the project.
The recruiting pitch is powerful: unrivaled compute per researcher, a shot at building the best open-source model family, and access to over 2 billion Daily Active Users. The offers that generally range from $200M to $300M per researcher for 4 years also strengthens this pitch. As such Meta has acquired awesome talent from OpenAI, Anthropic, and many other firms.
…While some have noted that Zuckerberg “settled” for Scale AI, we do not think this is the case…core to many of the Llama 4 issues were data problems and the Scale acquisition is a direct move to address that.
It’s interesting to see while EPS estimates for 2025 was revised upward after 1Q’25, 2026 and 2027 estimates are still somewhat below pre-liberation week. Given the level of opex spending increase in AI that Meta essentially unveiled in the last couple of months and may have more impact to 2026 numbers, I wonder if there is further downward adjustments needed for 2026.

I received a copy of the book “The Wealth Ladder”. The book had an interesting table dissecting wealth in six levels. One can, of course, not feel quite rich despite being on level 4 even though they are, objectively speaking, the “top 1%” in the world if they are “stuck” there for quite some time.
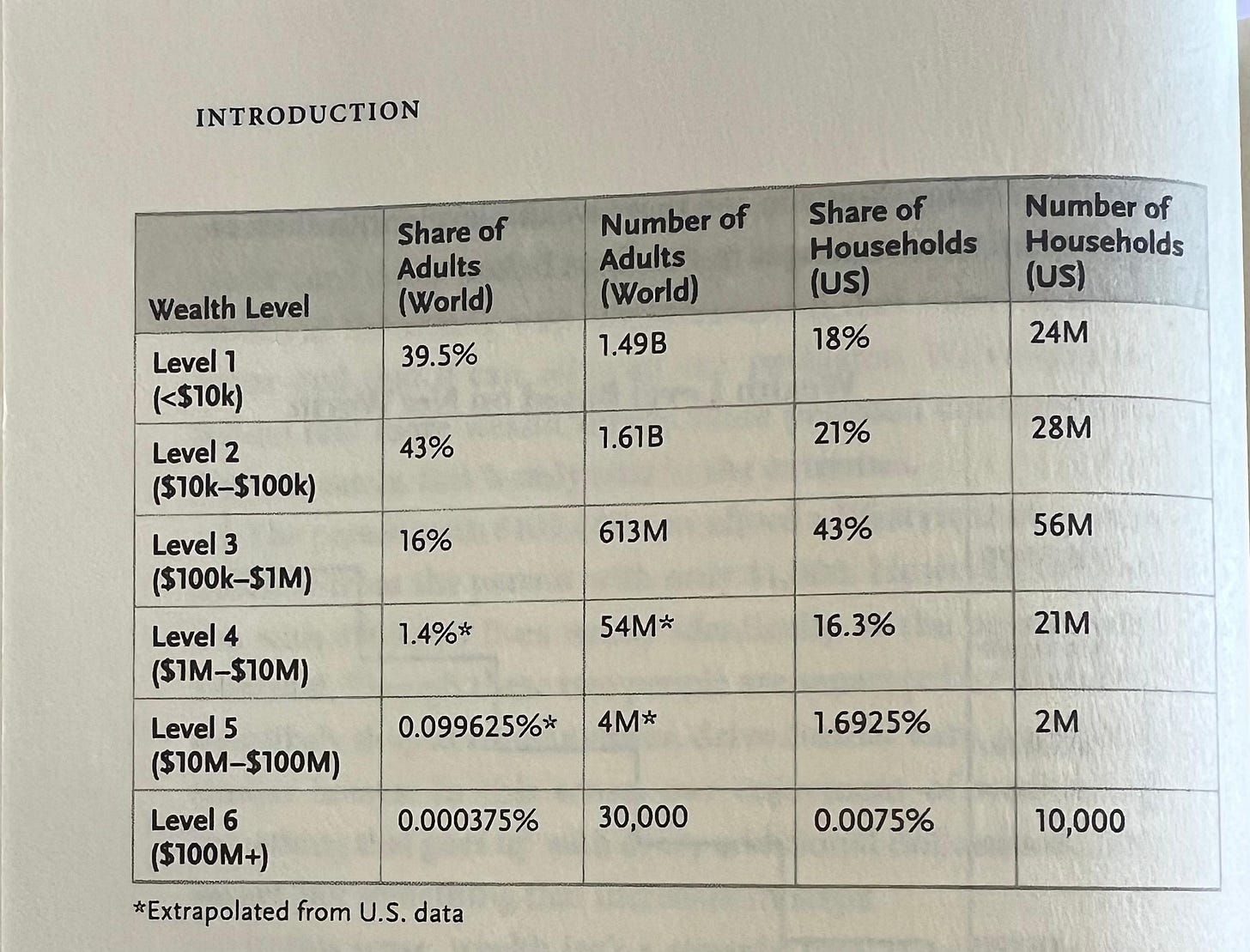
But being “stuck” in level 4 is sort of expected. The book had a couple of good paragraphs about it:
Imagine you just hit Level 4 and you have $1 million in investments. If you don’t save another dollar and your investments return 5 percent per year (after inflation), it would take forty-seven years for you to get to $10 million. Of course, you probably aren’t going to stop saving once you hit $1 million. So let’s assume you save $100,000 after tax per year, a significant sum of money. How long would it take you to get to $10 million with a 5 percent annual return? Twenty-eight years. What about if you saved $200,000 per year? Then it would take about twenty-one years. What about if you saved $300,000 annually? It still takes seventeen years!
As you can see, even with a very high-paying job (e.g., $500,000 per year or more), it will take multiple decades to get to Level 5. And note that this would be after you’ve already made it to Level 4. If you manage to get to Level 4 in your thirties or forties, this is doable, but will still require a lot of effort. Unfortunately, as I will cover later, only 5 percent of people in their thirties and 15 percent of people in their forties are in Level 4. Since the median age for those in Level 4 is sixty-two, most people don’t enter Level 4 until later in life. This means that the typical person in Level 4 would need to work an extremely demanding job into their seventies and eighties to get to Level 5. And who wants to do that?
As they say, five million is a nightmare 😂
While it is easy to mock people in level 4 complaining about anything, I do think the experience of climbing the ladders over time may be more satisfying experience to most people, and people who are stuck likely crave the experience of graduating one level to another. Ultimately, wealth does feel mostly psychological in my opinion after a certain threshold. If you’re born in level 1 but currently in level 3, you may feel much happier than someone who was in level 4 but ended up in level 3 even though objectively they may both have similar wealth.
Current Portfolio:
Please note that these are NOT my recommendation to buy/sell these securities, but just disclosure from my end so that you can assess potential biases that I may have because of my own personal portfolio holdings. Always consider my write-up my personal investing journal and never forget my objectives, risk tolerance, and constraints may have no resemblance to yours.